ここでは、衛星リモートセンシングデータから生成された地表面温度 (Land Surface Temperature: LST) と植生指数 (Normalized Difference Vegetation Index: NDVI) を使って、空間統計学の解析を通じて、LSTを推定し、観測値、推定値、残差を可視化する演習を説明しています。統計処理用にRを、またデータの前処理にシェルスクリプト、Python、可視化にQGISを使っています。
LST, NDVIの定義式については、「反射率、輝度温度、標高データを用いた土地被覆分類」に記載されています。
また本演習では、NASAが打ち上げて運用しているModerate Resolution Imaging Spectrometer (MODIS) というセンサで取得された画像を利用しています。空間分解能250 m~1 kmで、同一地点を毎日取得できる低空間分解能の衛星センサです。画像の空間解像度は落ちますが、その代わりに毎日画像を取得できることで、広域の長期間にわたる時系列変化を調べるのに適しています。36バンドで得られたデータから、陸域だけでなく、海洋、大気、雪氷圏の解析に役立つ様々なプロダクトが生成されています。
|
|
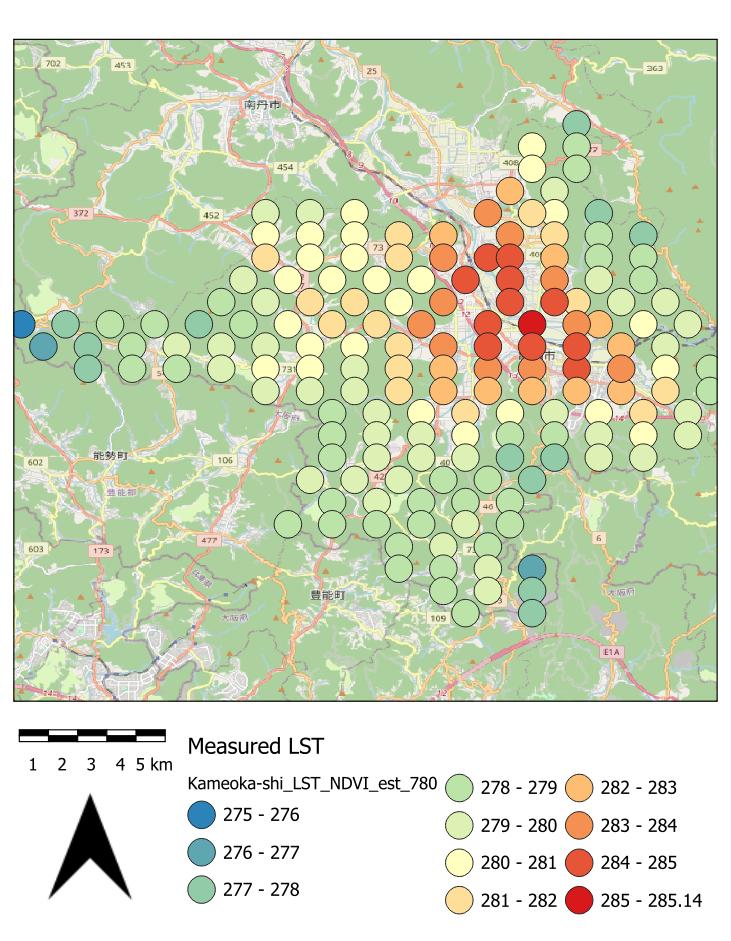
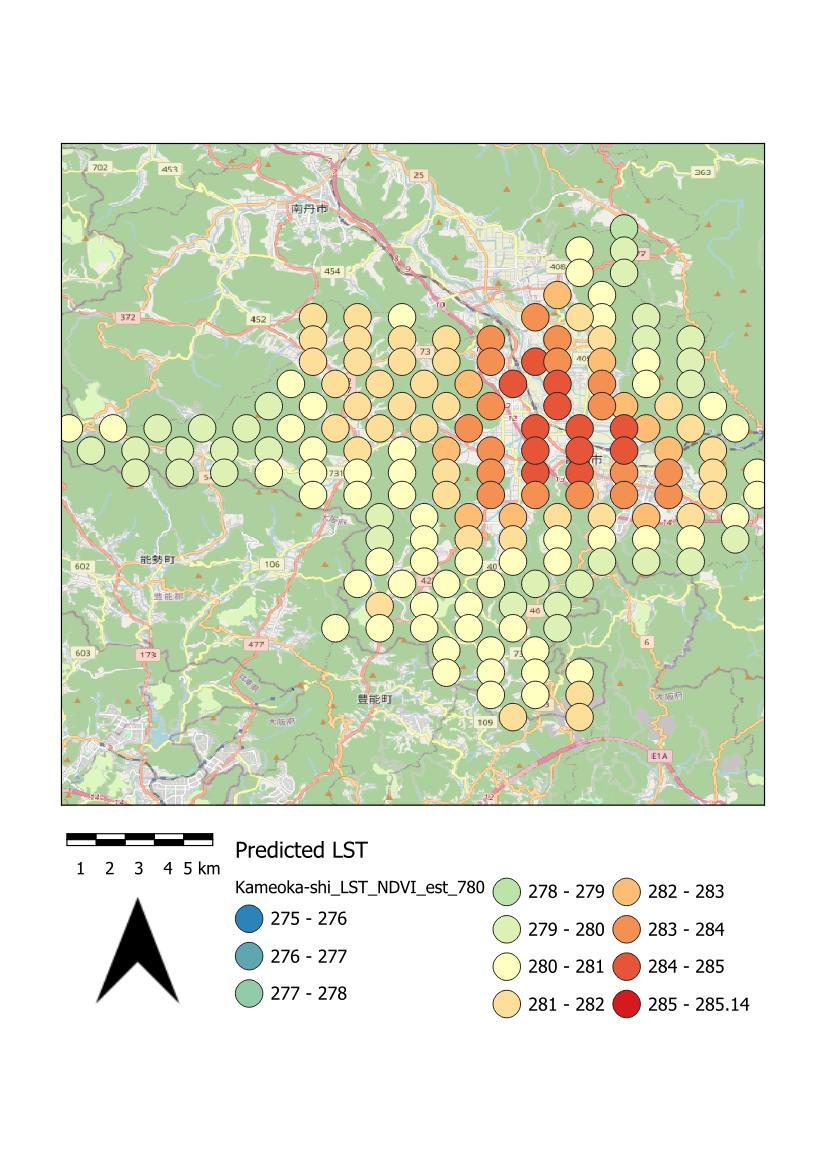
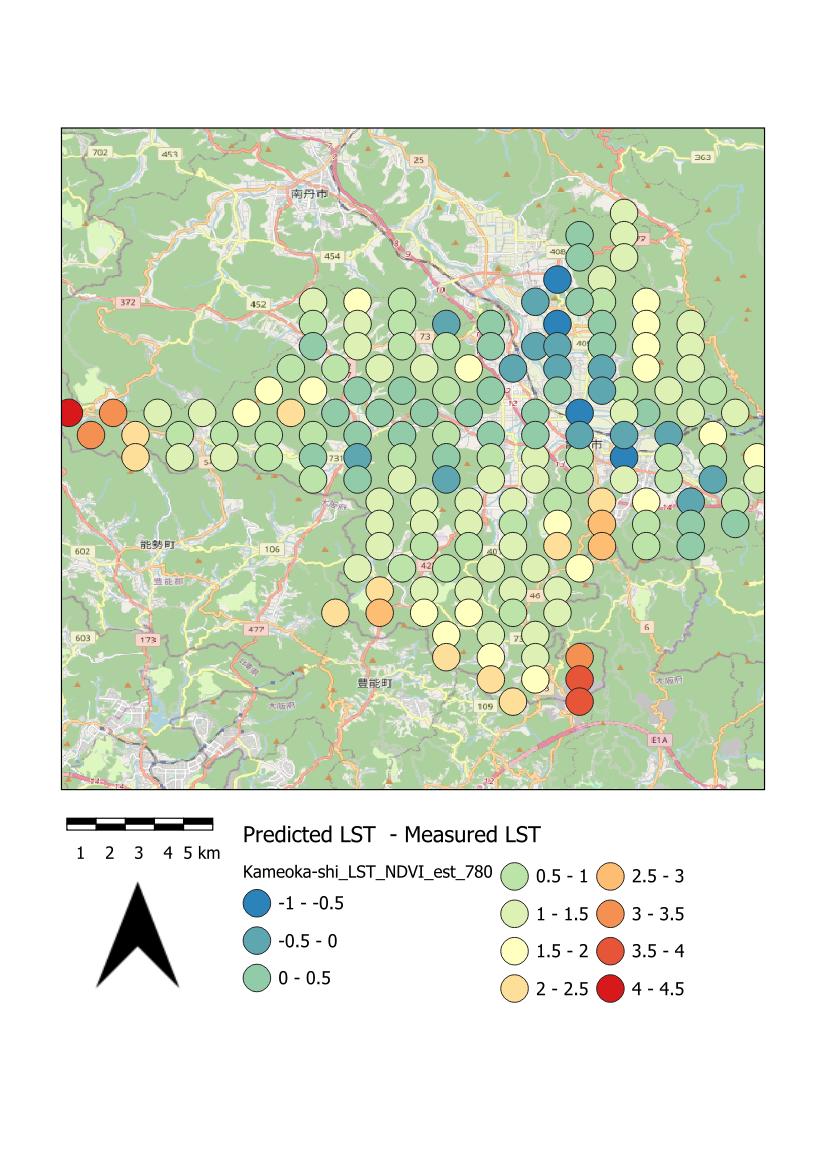
| この演習で最終的に得られる結果の一例:亀岡市のDOY=780(2012年1月1日をDOY=1)時における地表面温度(LST)の衛星画像の観測値(左)、推定値(中)、残差(右) |
注意:以下で(参考)と書いてあるところは、演習中には自分で処理する必要はなく、既に用意されたデータ等を使用すればよい。今後、自分でさらに処理する時のために記述した。
MODISというセンサで取得されたデータから生成されるLST, NDVIのプロダクトは、各々8日間、16日間ごとに処理される。通常、WebサイトからLST, NDVIのプロダクトをダウンロードする際には対象期間に含まれるプロダクトを全てダウンロードする。
本演習では、LST, NDVIのプロダクトを一つの表にまとめる。LSTは8日間ごとにファイルが存在するが、処理で必要とされるのは16日ごとのファイルであり、一旦ダウンロードしたファイルのうちコピーするファイルを選別する必要が出てくる。手作業でコピーすることもできるが非効率的で、シェルスクリプトを使うと簡単に実行できる。そのシェルスクリプトを実行する環境を構築するために、cygwinをインストールする。
以下のサイトからインストーラーをダウンロードし、インストールする。
Rの解説ページRjpWiki
演習では、演習内に提示するデータを利用して処理するが、自分たちでも直接LST, NDVIのプロダクトをダウンロードできる。
(参考)2022年3月修士課程修了の楠瀬智也氏が残してくれた、LST, NDVIプロダクトのダウンロードおよび処理の手引書
空間統計解析の前に、上記のデータを処理する必要がある。
衛星画像(データ)の処理においてはファイル数が多数に上り、またファイル名に規則性があることから、自動的に一括処理するシェルスクリプトが多用される。元々、筆者は1990年代後半から2000年代半ばまでUNIX (Solaris, HP-UX) で処理することが多く、シェルスクリプトを多用していた。現在はWindowsでの作業が多く、cygwinを使うことがあるため、cygwinを前提に下記の通り説明している。一括して大量のファイルをコピーしたり、ファイル名を変更したりできれば、別にシェルスクリプトでなくても構わない。
(参考)シェルスクリプト講座: [基礎編] [制御文編] [実例編1] [実例編2]
まず、この作業で想定している、フォルダ(またはディレクトリ)とファイルの構造を下記に示す。ドライブDの下のフォルダ名を「rsgis」としているが、この名前は何でも構わない。
C:\Program Filesなど
D:\rsgis
|__ Data
|__ Prefecture_LST (ダウンロードしてきたLST:8日ごと)
|__ Aichi
|__ Agui-cho_2012001_LST.csv
|__ Agui-cho_2012009_LST.csv
|__ Agui-cho_2012017_LST.csv
|__ Akita
|
(他の都道府県のフォルダが存在)
|__ Prefecture_NDVI(ダウンロードしてきたNDVI:16日ごと)
|__ Aichi
|__ Agui-cho_2012001_NDVI.csv
|__ Agui-cho_2012017_NDVI.csv
|__ Agui-cho_2012033_NDVI.csv
|__ Akita
|
(他の都道府県のフォルダが存在)
|__ Prefecture(上記2つからコピーしたファイルの保存用)
|__ Prefecture_rst(4年間のLSTとNDVIを1つにまとめたファイルを保存)
Cygwinで実行する内容:打ち込むコマンドを赤字で示す。ここでは、全ての都道府県のデータをコピーする処理を示しているが、演習では特定の都道府県名を明記して処理する。。
$ pwd ← 現在のディレクトリを表示 /home/susaki $ cd /cygdrive/d/rsgis ← データのあるディレクトリへ移動 $ ls ← ファイルやディレクトリを表示 (結果が表示される:省略) $ ./copy.sh
copy.shの中身
#!/usr/bin/bash
# LSTデータ:NDVIに合わせて16日おきのデータをコピー
# NDVIデータ:丸ごとコピー
DIR_OUT=Data/Prefecture
DIR_IN1=Data/Prefecture_LST # 001, 009, 017と8日おきのデータ
DIR_IN2=Data/Prefecture_NDVI # 001, 017, 033と16日おきのデータ
# 対象年:開始、終了、間隔
year_st=2012
year_end=2015
year_intv=1
# 対象DOY (Day of year):開始、終了、間隔
doy_st=1
doy_end=353
doy_intv=16
# LSTデータのコピー:NDVIに合わせて16日おきのデータをコピー
for dir in `ls ${DIR_IN1}`
do
echo "++++++ ${dir} ++++++"
dirpath_in=${DIR_IN1}/${dir}
dirpath_out=${DIR_OUT}/${dir}
echo ${dirpath_in}
echo ${dirpath_out}
if [ ! -e ${dirpath_out} ] # 出力先ディレクトリが存在しない場合
then
mkdir ${dirpath_out} # 出力先ディレクトリを作成
fi
year=${year_st}
while [ ${year} -le ${year_end} ]
do
echo "***** ${year} *****"
doy=${doy_st}
while [ ${doy} -le ${doy_end} ]
do
doyid=`printf "%03d" ${doy}` # DOYの3桁表示
yeardoy=${year}${doyid}
echo "----- ${yeardoy} -----"
cp ${dirpath_in}/*${yeardoy}*csv ${dirpath_out}
doy=`expr ${doy} + ${doy_intv}`
done
year=`expr ${year} + ${year_intv}`
done
done
# NDVIデータのコピー:全ファイルをそのままコピー
for dir in `ls ${DIR_IN2}`
do
echo "++++++ ${dir} ++++++"
dirpath_in=${DIR_IN2}/${dir}
dirpath_out=${DIR_OUT}/${dir}
echo ${dirpath_in}
echo ${dirpath_out}
if [ ! -e ${dirpath_out} ] # 出力先ディレクトリが存在しない場合
then
mkdir ${dirpath_out} # 出力先ディレクトリを作成
fi
cp ${dirpath_in}/*csv ${dirpath_out}
done
以下、簡単に処理の方針を示す。
#!/usr/bin/env python
# coding: utf-8
import pandas as pd
import numpy as np
import os
import glob
import csv
# DOYのリスト作成
year_list = list(range(2012, 2016))
doy_list = list(range(1, 365, 16))
doy_name = []
for year in year_list:
for doy in doy_list:
doy_tmp = f'{doy:03}' # 数字を3桁の文字として出力
doy_name_tmp = str(year) + doy_tmp # 例:2012 + 001 -> 2012001
doy_name.append(doy_name_tmp)
# ファイルが存在するフォルダのPATH
path0 = "./Data/Prefecture/Kyoto"
path0_out = "./Data/Prefecture_rst/Kyoto"
# プロダクトリスト(2種類)
prods = ['LST', 'NDVI']
files0 = os.listdir(path0)
f0 = files0[0:]
num0 = len(f0)
# 市町村名の抽出
areas = []
#for infile in f0:
for i in range(num0):
# '2'を使って文字列を分割
# 京都市のファイルが不規則に命名されているため、'_'では失敗する
strtmp = f0[i].split('2')
areas.append(strtmp[0])
# 市町村名の重複削除
areas_unique = list(dict.fromkeys(areas))
num_areas = len(areas_unique)
# 市町村単位で2012001_LST(NDVI), ..., 2015361_LST(NDVI)のファイルを処理
for area_name in areas_unique:
# Lat, Lonの和集合作成:開始
pathtmp = path0 + "/" + area_name + "*.csv"
print(pathtmp)
area_file = glob.glob(pathtmp) # 該当する市町村のファイルのみ抽出
print(area_file)
num_area_file = len(area_file)
ll = []
for i in range(1):
# 各CSVファイルのデータを読み込み
with open(area_file[i], encoding='utf8', newline='') as f:
csvdata = csv.reader(f)
lines = [row for row in csvdata]
num_lines = len(lines)
for j in range(1, num_lines):
#print(j, num_lines)
ll_tmp = [lines[j][1], lines[j][2]]
ll.append(ll_tmp)
print(i, 'old ll = ', len(ll))
for i in range(1, num_area_file):
# 各CSVファイルのデータを読み込み
with open(area_file[i], encoding='utf8', newline='') as f:
csvdata = csv.reader(f)
lines = [row for row in csvdata]
num_lines = len(lines)
for j in range(1, num_lines):
ll_tmp = [lines[j][1], lines[j][2]]
ll.append(ll_tmp)
#重複削除
print(i, 'old ll = ', len(ll))
ll2 = []
for line in ll:
if line not in ll2:
ll2.append(line)
ll = ll2
print(i, 'new ll = ', len(ll))
# 該当するデータを格納。存在しない場合にはN/Aを格納
header = ['Lon', 'Lat']
data = ll
num_lines_all = len(data)
# Lat, Lonの和集合作成:終了
# 2012001, ..., のように順番にファイルが存在するか点検
# ファイルが存在しない場合、その日のデータには全てN/Aを格納
flag_data = [0] * num_lines_all # データの有無のフラッグ
# DOYのリスト順にファイルが存在すれば開く
for yeardoy in doy_name:
for prod in prods:
print(yeardoy, prod)
yrdyprod = yeardoy + prod
flag_file = 0
for afile in area_file:
if afile.find(prod) > 0 and afile.find(yeardoy) > 0:
#print(afile)
flag_file = 1
break
if flag_file == 1:
# 各CSVファイルのデータを読み込み
with open(afile, encoding='utf8', newline='') as f:
csvdata = csv.reader(f)
lines = [row for row in csvdata]
num_lines = len(lines)
# "2012001LST"などをヘッダーに追加
header.append(yrdyprod)
# フラッグの初期化
for k in range (num_lines_all):
flag_data[k] = 0
# Lat, Lonが一致すればLST(NDVI)データの書き込み
for j in range(1, num_lines):
for k in range(num_lines_all):
if lines[j][1] == data[k][0] and
lines[j][2] == data[k][1]:
data[k].append(lines[j][3]) # LST or NDVI
flag_data[k] = 1
break
for k in range(num_lines_all):
if flag_data[k] == 0:
data[k].append('N/A')
else: # ファイルが存在しない場合
# "2012001LST", "2012001NDVI"などをヘッダーに追加
header.append(yrdyprod)
for k in range(num_lines_all):
data[k].append('N/A')
# ファイルへの出力
file_path = path0_out + "/" + area_name + "LST_NDVI.csv"
data_tmp = data
data_tmp.insert(0, header)
with open(file_path, "w", encoding="utf-8") as fout:
writer = csv.writer(fout, lineterminator='\n')
writer.writerows(data_tmp)
以下の手順に従って入力していく。「QGIS, Rを用いた公示地価データの空間統計分析:静的な時空間モデリング」と同様に、低ランクガウス過程による時空間統計解析を行う。
下記の例では、各DOYの観測値、推定値、残差(=推定値-観測値)の結果を出力している。
#ライブラリの読み込み
install.packages("sp")
install.packages("mgcv")
install.packages("spacetime")
library(sp)
library(mgcv)
library(spacetime)
#データの読み込み
dir <- "Data/Prefecture_rst/Kyoto"
city_name <- "Kameoka-shi"
infile <- paste0(dir, "/", city_name, "_LST_NDVI.csv", sep = "")
dat <- read.csv(infile)
# 奇数:モデル作成用, 偶数:検証用
dat_tmp <- split(dat, rep(c("odd", "even")))
dat1 <- dat_tmp$odd # モデル作成用
dat2 <- dat_tmp$even # 検証用
# 各年度のデータを下記の並びに整理
# Lon, Lat, LST, NDVI, Time
dat1a <- data.frame(Lon=dat1$Lon, Lat=dat1$Lat,
LST=dat1$X2012001LST, NDVI=dat1$X2012001NDVI, Time=1)
dat2a <- data.frame(Lon=dat2$Lon, Lat=dat2$Lat,
LST=dat2$X2012001LST, NDVI=dat2$X2012001NDVI, Time=1)
year_list <- list(2012:2015)
doy_list <- seq(from = 1, to = 353, by = 16)
doy2012_list <- paste0("2012", sprintf("%03d", doy_list))
doy2013_list <- paste0("2013", sprintf("%03d", doy_list))
doy2014_list <- paste0("2014", sprintf("%03d", doy_list))
doy2015_list <- paste0("2015", sprintf("%03d", doy_list))
total_doy2012_list <- doy_list
total_doy2013_list <- 366 + doy_list
total_doy2014_list <- 366 + 365 + doy_list
total_doy2015_list <- 366 + 365*2 + doy_list
doy_all <- c(doy2012_list, doy2013_list, doy2014_list, doy2015_list)
tdoy_all <- c(total_doy2012_list, total_doy2013_list,
total_doy2014_list, total_doy2015_list)
# 2012017, 2012033などのリストを生成
num_doy <- length(doy_all)
for (i in 2:num_doy) { # "2012001"は除外するため、i=2から開始
# "X2012017LST", "X2012017NDVI"のような列名を作成
lstid <- paste0("X", doy_all[i], "LST")
ndviid <- paste0("X", doy_all[i], "NDVI")
timeid <- tdoy_all[i]
dat1b <- data.frame(Lon=dat1["Lon"], Lat=dat1["Lat"],
LST=dat1[lstid], NDVI=dat1[ndviid], Time=timeid)
dat2b <- data.frame(Lon=dat2["Lon"], Lat=dat2["Lat"],
LST=dat2[lstid], NDVI=dat2[ndviid], Time=timeid)
# 列名を"X2012017LST"から"LST"へ置換
dat1b <- dplyr::rename(dat1b, LST=lstid)
dat2b <- dplyr::rename(dat2b, LST=lstid)
dat1b <- dplyr::rename(dat1b, NDVI=ndviid)
dat2b <- dplyr::rename(dat2b, NDVI=ndviid)
dat1a <- rbind(dat1a, dat1b)
dat2a <- rbind(dat2a, dat2b)
}
dat1 <- dat1a
dat2 <- dat2a
# N/Aが含まれる行を削除
dat1tmp <- subset(dat1, !(is.na(dat1$LST)))
dat1 <- dat1tmp
dat1tmp <- subset(dat1, !(is.na(dat1$NDVI)))
dat1 <- dat1tmp
dat2tmp <- subset(dat2, !(is.na(dat2$LST)))
dat2 <- dat2tmp
dat2tmp <- subset(dat2, !(is.na(dat2$NDVI)))
dat2 <- dat2tmp
# LSTを文字列として認識させたいので、数値へ変換
dat1$LST <- as.numeric(dat1$LST)
dat2$LST <- as.numeric(dat2$LST)
# 低ランクガウス過程による時空間統計解析の実行: dat1を使用
f1 <- LST ~ te(Lon, Lat , Time, k=c(50,10),d=c(2,1)) +
s(NDVI) + s(Lon) + s(Lat) + s(Time)
model1 <- gam(f1, data= dat1)
# 結果の出力
est_rst <- paste0(dir, "/", city_name, "_LST_NDVI_rst.txt", sep = "")
sink(est_rst)
summary(model1)
sink()
# 検証: dat2を使用
pred_rst <- predict(model1, newdata = dat2, se.fit = TRUE, interval =
'confidence', level = 0.95)
pred_rst_table <- data.frame(dat2[, c("Lon", "Lat", "Time", "LST")], Pred=pred_rst$fit)
# 検証結果の出力
old.op <- options(max.print=2147483647) # 出力桁数の上限の変更
outfile <- paste0(dir, "/", city_name, "_LST_NDVI_val_rst.txt", sep = "")
sink(outfile)
pred_rst_table
sink()
# 残差の計算
pred_rst_table$LST <- as.numeric(pred_rst_table$LST)
dif <- pred_rst_table$Pred - pred_rst_table$LST
pred_rst_table <- cbind(pred_rst_table, dif)
# DOY別に予測結果の出力
# for文内でsink関数を使う時には、print()を使って出力
for (i in 1:num_doy) {
pred_rst_table_tmp <- pred_rst_table[pred_rst_table$Time == tdoy_all[i], ]
outfile <- paste0(dir, "/", city_name, "_LST_NDVI_est_", tdoy_all[i], ".txt", sep = "")
sink(outfile)
print(pred_rst_table_tmp)
sink()
}
低ランクガウス過程による時空間統計解析の実行結果(亀岡市の例)
Family: gaussian
Link function: identity
Formula:
LST ~ te(Lon, Lat, Time, k = c(50, 10), d = c(2, 1)) + s(NDVI) +
s(Lon) + s(Lat) + s(Time)
Parametric coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 290.93436 0.01799 16174 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Approximate significance of smooth terms:
edf Ref.df F p-value
te(Lon,Lat,Time) 269.045 349.267 90.077 < 2e-16 ***
s(NDVI) 7.007 8.099 59.630 < 2e-16 ***
s(Lon) 8.103 8.358 4.168 2.44e-05 ***
s(Lat) 7.378 7.991 6.236 < 2e-16 ***
s(Time) 9.000 9.000 3775.343 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
R-sq.(adj) = 0.952 Deviance explained = 95.3%
GCV = 4.3025 Scale est. = 4.2026 n = 12989
まず、プロジェクトに座標系を与える。新規プロジェクトを立ち上げてから、下記のように設定する。
次に、推定結果をQGIS上で表示する。一例として、上記の出力結果の「Kameoka-shi_LST_NDVI_est_780.txt」をQGIS上に取り込でいく。自動的に、各列の名前(フィールド名)を読み込んでくれる。
注意:Rで出力されたファイルはカンマ区切りのCSVファイルではなく、スペースの長さが一定ではない空白区切りのファイルである。そのため、以下の設定が必要になる。
下記のフィールド名でデータが読み込まれるはずである。
次に、背景画像と重ね合わせて表示させる。好きな背景を選んで構わない。
最後に、上記で作成した「Kameoka-shi_LST_NDVI_est_780.txt」を表示させる。3種類の図を作成するが、下記の「値」において(1)LST, (2)Pred, (3)dif を指定していく。
その結果をQGISでの「印刷レイアウト」の機能を使って、スケールバーや方位記号等を追加し、整形していく。この処理は他のWebサイトを参照して、各自で達成してほしい。一例として、下記のような図が得られる。
|
|
| 亀岡市のDOY=780(2012年1月1日をDOY=1)時における地表面温度(LST)の衛星画像の観測値(左)、推定値(中)、残差(右)。凡例のモードは「丸め間隔」を選んだ。 |
各自で以下の課題に取り組んで、レポートを作成し、PandA上のフォルダに提出する。提出後はメールにて連絡する。
[GRASSのインストール、標高データを用いた地滑り危険度マップの作成]
[植生指数 (NDVI) の計算、表示]
[標高データ (SRTM)の表示、植生指数 (NDVI) の3次元表示]
[反射率、輝度温度、標高データを用いた土地被覆分類]
[QGIS, Rを用いた公示地価データの空間統計分析:空間的自己回帰モデル]
[QGIS, Rを用いた公示地価データの空間統計分析:静的な時空間モデリング]
[QGIS, Rを用いた衛星データ(LST, NDVI)の時空間統計分析:静的な時空間モデリング]
[QGIS, Rを用いた衛星データ(LST, NDVI)の時空間統計分析:静的な時空間モデリングの応用事例]
[Pythonを用いた空間統計分析のための衛星データ(LST, NDVI)の処理1(市町村別データの生成)]
[Pythonを用いた空間統計分析のための衛星データ(LST, NDVI)の処理2(人口データの重みを加味した市町村別データの生成)]