Pythonを用いた空間統計分析のための衛星データ(LST, NDVI)の処理1
本Webページでは、本人の了承の下、2022年3月修士課程修了の楠瀬智也氏が残してくれたLST, NDVIプロダクトのダウンロードおよび処理の手引書をそのまま引用しています。ここに記して謝意を表します。
ここでは、衛星リモートセンシングデータから生成された地表面温度 (Land Surface Temperature: LST) と植生指数 (Normalized Difference Vegetation Index: NDVI) の自動処理を紹介します。Pythonを使って、WebサイトからNDVI・LSTデータを取得するところから始まり、投影変換を通じて、最終的にNDVI・LSTデータを日本全国の市区町村に分ける処理までを説明します。
LST, NDVIの定義式については、「反射率、輝度温度、標高データを用いた土地被覆分類」に記載されています。
本演習では、NASAが打ち上げて運用しているModerate Resolution Imaging Spectrometer (MODIS) というセンサで取得された画像を利用しています。空間分解能250 m〜1 kmで、同一地点を毎日取得できる低空間分解能の衛星センサです。画像の空間解像度は落ちますが、その代わりに毎日画像を取得できることで、広域の長期間にわたる時系列変化を調べるのに適しています。36バンドで得られたデータから、陸域だけでなく、海洋、大気、雪氷圏の解析に役立つ様々なプロダクトが生成されています。
1. WebサイトからNDVI・LSTデータの自動ダウンロード
MODISのサイトからNDVI・LSTのデータを、スクレイピングにより自動でダウンロードする処理(手動でダウンロードを行ってもよいが、手間がかかる)。
スクレイピングは10秒ごとにデータを取得している(過剰なアクセスにより弾かれるのを防ぐため)。そのため、処理には半日以上の時間を要することに注意。
ダウンロードする際にはユーザー名(User_name)・パスワード(password)をMODISのサイトから各々登録し、設定する必要がある。登録は以下のURLから行える。
(https://urs.earthdata.nasa.gov/profile)
このプログラムを実行する際に、同じ階層内に「Data」が生成され、更に「Data」フォルダ内に「NDVI_HDF」、「LST_HDF」フォルダが自動に生成される。
入手したHDFファイルはNDVI・LSTそれぞれ手動であらかじめNDVI_HDF、LST_HDFに格納しておくこと。画像データは不要であり、HDFファイルだけ入れておけばよい。
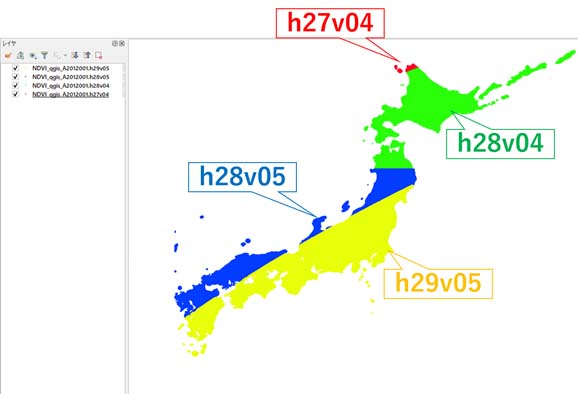
また、プロダクトはSinusoidalという投影法で保存されていることに注意。日本の範囲内に含まれているNDVI・LSTを選択する場合は、"h27v04","h28v04","h28v05","h29v05"というタイル名を選定する。
(
https://suzaku.eorc.jaxa.jp/GCOM_C/users_portal/faq/docs/GCOM-C_Products_Users_Guide_entrylevel__attach4_jp_191007.pdf
のp.22に記載されている。日本に該当する箇所が"h27v04","h28v04","h28v05","h29v05"に相当する。)
デフォルトでは2012年〜2015年のデータを取得しているが、任意の年の取得が可能である。ほしいデータの時系列データを変更するには、配列の数を変えればよい。
例えばLST・8日間プロダクト・1 km解像度の場合では、[545:729]が2012年〜2015年のデータ分に相当する配列だが、2012年〜2016年のデータが欲しい場合は、[545:775]とすれば、その分の配列が出力される。その都度出力を確認し、欲しいデータの配列となるように適宜調整すればよい。
2. HDFファイルの加工
取得したHDFファイルを、加工しやすいようにするため、CSVファイルに変換する処理。
処理内容については、以下のURLを参考にするとわかりやすい。
参考:http://pen.envr.tsukuba.ac.jp/‾torarimon/?cmd=view&p=HDF4
NDVI・LSTのHDFファイルには様々な情報が格納されている構造体でありそこから欲しい情報を取り出す必要がある。
LSTは「'LST_Day_1km'」、NDVIは「'1 km 16 days NDVI'」を選択し、抽出を行う。
HDFファイルをPythonで開くには「python-hdf4」というモジュールが必要であり、適宜インストールする必要がある。Python環境のコマンドプロンプトで下記のように実行すればよい。
$ sudo pip3 install python-hdf4
このプログラムの実行により、「Data」フォルダ中に「NDVI_Before_change_of_coordinate」、「LST_Before_change_of_coordinate」フォルダが自動で生成され、このフォルダ内にCSVとしてNDVI・LSTデータが記録される。この時記録されるNDVI・LSTデータはSinusoidal図法に基づく座標系として保存されていることに注意(座標変換を行う前なので「Before_change_of_coordinate」という名前がフォルダに付いている)。
3. ファイルの移動1
上記で行った「HDFファイルの加工」処理結果を、領域("h27v04","h28v04","h28v05","h29v05")毎に応じて各フォルダに振り分ける。ここで、Before_change_of_coordinateフォルダ内に、自動的に「〇〇_h27v04」、「〇〇_h28v04」、「〇〇_h28v05」、「〇〇_h29v05」(〇〇はLST or NDVI)というフォルダが生成され、それぞれ振り分けられる。
4. 座標投影変換
|
Sinusoidalの座標系を平面直角座標系に変換する処理。"h27v04", "h28v04", "h28v05", "h29v05" の4領域ごとに若干処理が異なるため、4つにプログラムを分けている。これらのプログラムをそれぞれ実行する必要がある。
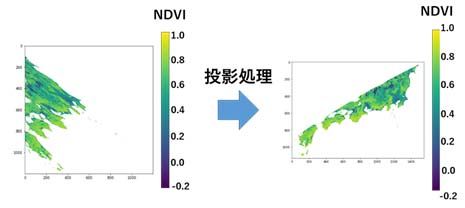
MODISのデータから得られる日本のNDVI・LST分布の出力画像は歪んでいるが,これは投影される座標系が正弦曲線図法であることに由来する。変換にあたっては,緯度の値Xはそのまま保持し,経度Yについては以下のようにして変換を行っている。
(X'=X/(cos (Y*PI/180)))
例えば、h29v05に対してこのプログラムの処理を実行すると、図1のように投影処理がなされる。
処理プログラムの作成にあたっては、下記のpp.29〜32を参考とした。
SGLI 高次プロダクトフォーマット説明書
これらの処理を"h27v04","h28v04","h28v05","h29v05" の4領域それぞれで実行する。
実行後、「NDVI_After_change_of_coordinate」、「LST_After_change_of_coordinate」というフォルダが自動生成され、座標投影されたCSVファイルが保存される。
なお、保存形式は3列のデータであり、「経度(X)」、「緯度(Y)」、「NDVI(or LST)」が保存される。
※実行には1〜2時間程度かかることに注意。
ここまでの出力結果の一例をQGIS等のGISソフトで出力すると、図2のように日本をかたどったような分布になっている。このことから、座標の変換が成功したと判断できる。
|

図1:Sinusoidal図法から正弦曲線図法への変換結果
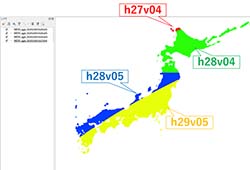
図2:日本列島において4領域を統合した結果。NDVIの2012001(2012年1月1日)のデータを使用した例。
|
5. ファイルの移動2
4.で行った処理を、領域("h27v04", "h28v04", "h28v05", "h29v05")毎に応じて各フォルダに振り分ける。処理後、After_change_of_coordinateフォルダ内に、自動的に「〇〇_h27v04」、「〇〇_h28v04」、「〇〇_h28v05」、「〇〇_h29v05」(〇〇はLST or NDVI)というフォルダが生成され、それぞれ振り分けられる。
6. ファイルの統合
5.で得られた投影後のLST・NDVIを統合し、日本全体のエリアのNDVI・LSTを取得するプログラム。ファイル名は「●●_concat.csv」という形で保存される。また、実行後は「NDVI_ALLJapan」「LST_ALLJapan」というフォルダが自動生成され、このフォルダ内にファイルが保存される。
7. 属性の付与
※きわめて実行に時間がかかります。他にいい方法が見つかれば、そちらを使ってください。
QGIS等のGISソフトを用い、⑥で得られた日本全国のNDVI・LSTデータを市区町村ごとに切り分ける。その際、GISソフトの「クリップ」を用いて処理を行う。
初めに、「全国市区町村界データ」を以下のURLからダウンロードする。中身は日本全国の市区町村データが含まれたポリゴンデータ(shpファイル)である。
全国市区町村界データ
このポリゴンデータは、ポリゴン中で自己交差が発生しており、クリップ処理の際にエラーが生じる原因となる。そのため、このshpファイルを使用する前に自己交差を解消する下処理を行う必要がある。以下にその下処理についての手順を説明する。
7.1. ポリゴンの自己交差の解消法
|
参考Webページ:
http://anznd1.xsrv.jp/?p=139
-
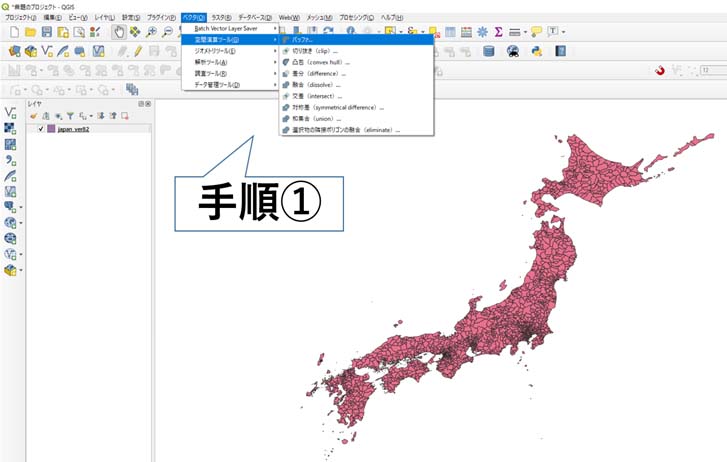
japan_ver82.shp(現在の最新版はjapan_ver83.shp)をQGIS上で読み込み、「ベクタ」→「空間演算ツール」→「バッファ」を選択する(図3参照)。
-
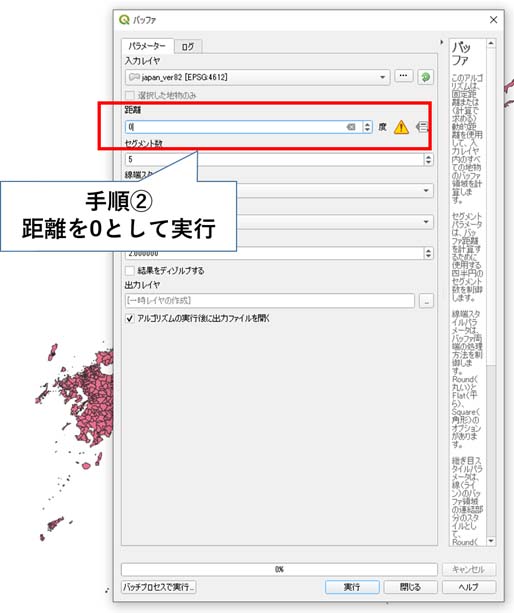
バッファの「距離」を0として実行する(図4参照)。他のパラメータは変えなくてよい。
-
出力されたレイヤをshpファイルとして、エクスポートして保存する。
|
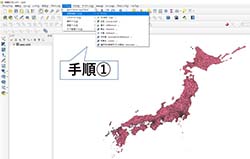
図3:「バッファ」の選択
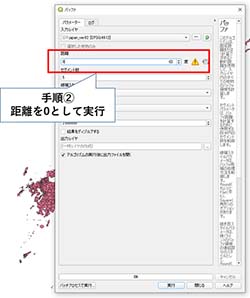
図4:「バッファ」用のパラメータ設定
|
7.2. クリッピング(属性の付加)処理
|
次に、自己交差を解消した日本のshpfileを使い、市区町村ごとの属性を、「NDVI_ALLJapan」「LST_ALLJapan」に含まれるNDVI・LSTデータに対して付加させる。QGIS等のGISソフトを用いて実行する。
以下に処理の手順を示す。
-
自己交差を解消した日本のshpfile(以下はjapan_Ver82_2.shpと記載する)と日本全国のNDVI・LSTが記録されたCSVファイル(以下はCONCATファイルと記載する)とをQGIS上に出力する。
-
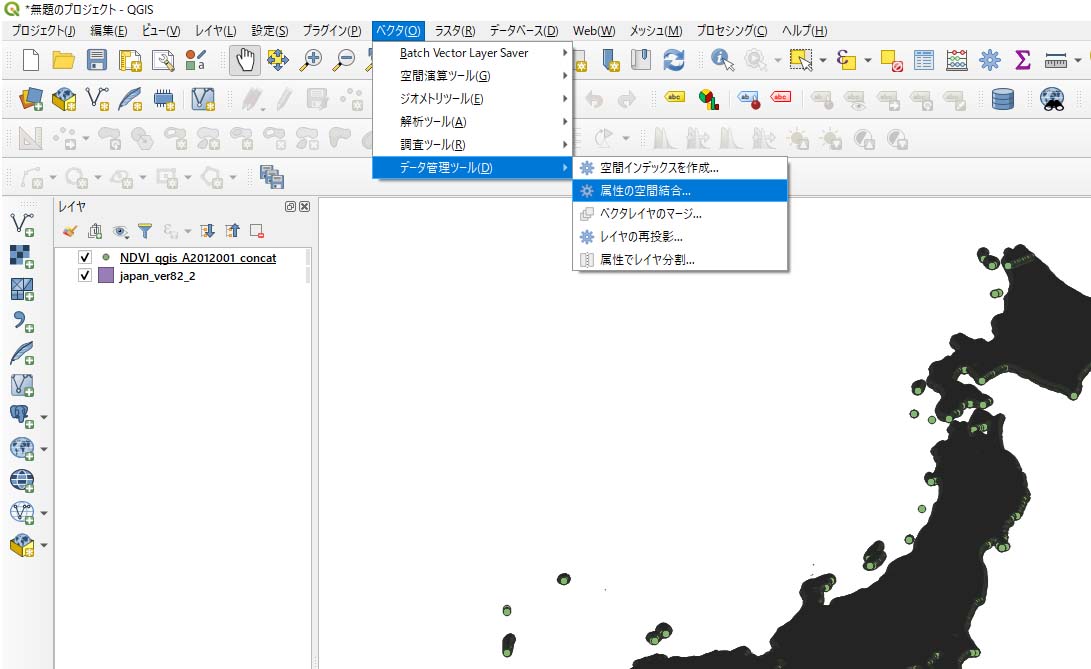
「ベクタ」→「データ管理ツール」→「属性の空間結合」を選択する(図5参照)。
-
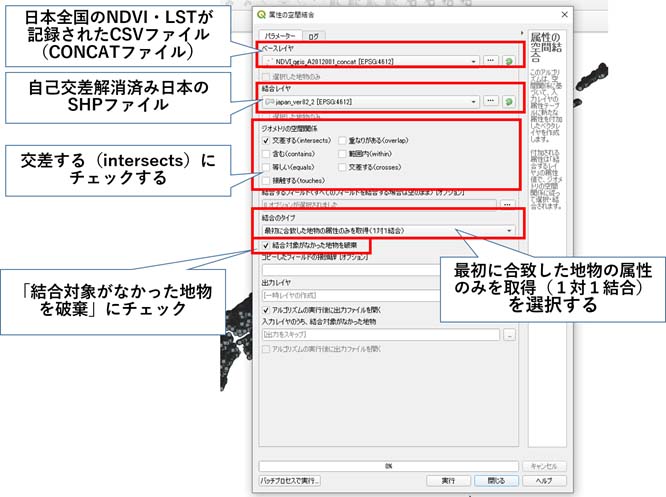
「ベースレイヤ」にCONCATファイル、「結合レイヤ」にjapan_Ver82_2.shpを入力する。また、ジオメトリの空間関係を「交差する(intersects)」、結合のタイプを「最初に合致した地物の属性のみを取得(1対1結合)」、「結合対象がなかった地物を破棄」にチェックを付け、実行する(図6参照)。
-
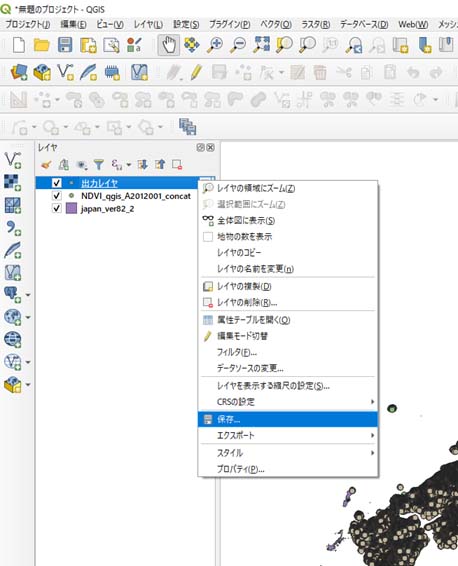
出力されるレイヤを右クリック → 保存 として、保存する。保存の際にはファイル名を処理前のCONCATファイルと一致させておく。保存時にはエンコーディングが「Shift_JIS」となっているか確認しておくこと(日本語の文字化けを防ぐため)(図7参照)。
また、保存先のフォルダは、あらかじめ「JapanAttributeData_NDVI」「JapanAttributeData_LST」というフォルダを手動で作成しておき、このフォルダ内にそれぞれ格納しておく。
-
手順①〜④を全てのCONCATファイルに対して実行する。
|
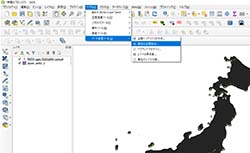
図5:属性の空間結合
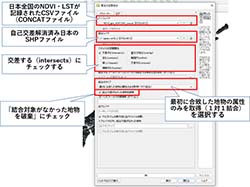
図6:ジオメトリの空間関係
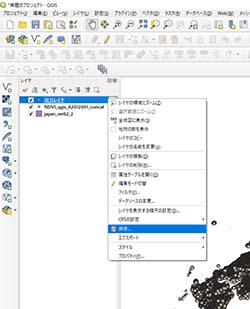
図7:出力レイヤの保存
|
8. 市町村単位での抽出、CSVファイルの出力
クリッピング(属性の付加)処理によって、今NDVI・LSTのデータには、「経度(X)」、「緯度(Y)」、「NDVI (or LST)」、「ポリゴン上に記載された各市区町村の属性」
が結合されている状態となっている。これらを、属性を活用することで市区町村ごとに切り分け、CSVファイルとしてまとめる処理を行う。
処理時には属性名「JCODE」を用いて都道府県別に分け、属性名「CITY_ENG」を用いて市区町村名をファイル名に記載する。
「JCODE」は都道府県ごとに値が決まっている。例えば北海道であれば「01???」、青森県→「02???」、岩手県→「03???」・・・、沖縄県→「47???」と分類される。
(???には市区町村のIDによりさらに細分化される3桁の数字が入る)
都道府県番号の参考資料
従って、上2桁の数値で都道府県を場合分けし、その中の市区町村の英語表記「CITY_ENG」を適宜取り出してファイル名に記載すれば、市区町村ごとにデータを保存することが可能となる。
保存されるファイルは「各市区町村のNDVI・LST」、「都道府県全体のNDVI・LST」の2種類が保存される。「都道府県全体のNDVI・LST」は「都道府県名_ZENTAI_取得日_NDVI(or LST).csv」という形で保存される。(例えば京都府全体のNDVI、2012年1月1日のものなら「Kyoto_ZENTAI_2012001_NDVI.csv」となる)
※処理には1〜2時間程度かかることに注意。
ここまでの処理で、日本全国の市区町村ごとのNDVI・LSTデータが座標値と共に取得出来ているはずである。
[GRASSのインストール、標高データを用いた地滑り危険度マップの作成]
[植生指数 (NDVI) の計算、表示]
[標高データ (SRTM)の表示、植生指数 (NDVI) の3次元表示]
[反射率、輝度温度、標高データを用いた土地被覆分類]
[QGIS, Rを用いた公示地価データの空間統計分析:空間的自己回帰モデル]
[QGIS, Rを用いた公示地価データの空間統計分析:静的な時空間モデリング]
[Rを用いた衛星データ(LST, NDVI)の空間統計分析]
[Pythonを用いた空間統計分析のための衛星データ(LST, NDVI)の処理1(市町村別データの生成)]
[Pythonを用いた空間統計分析のための衛星データ(LST, NDVI)の処理2(人口データの重みを加味した市町村別データの生成)]
[講義「リモートセンシングと地理情報システム(GIS)」のトップページ]
[須郫純一のページへ]
須郫純一 京都大学大学院 工学研究科社会基盤工学専攻 空間情報学講座