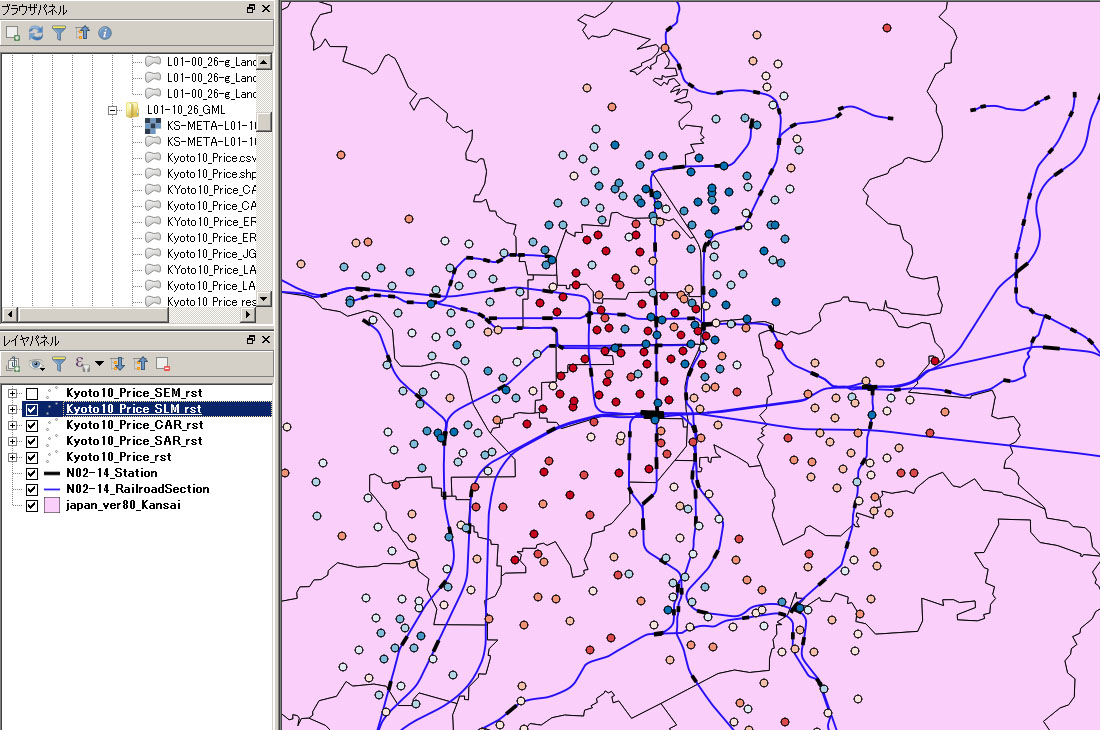
この演習で最終的に得られる画像
ここでは、QGIS, Rを用いて空間統計学の基礎的な演習を説明しています。
[GRASSのインストール、標高データを用いた地滑り危険度マップの作成]
[植生指数 (NDVI) の計算、表示]
[標高データ (SRTM)の表示、植生指数 (NDVI) の3次元表示]
[反射率、輝度温度、標高データを用いた土地被覆分類]
[QGIS, Rを用いた公示地価データの空間統計分析:空間的自己回帰モデル]
[QGIS, Rを用いた公示地価データの空間統計分析:静的な時空間モデリング]
|
この演習で最終的に得られる画像 |
以下のサイトからインストーラーをダウンロードし、インストールする。
空間統計解析の前に、上記のデータを処理する必要がある。
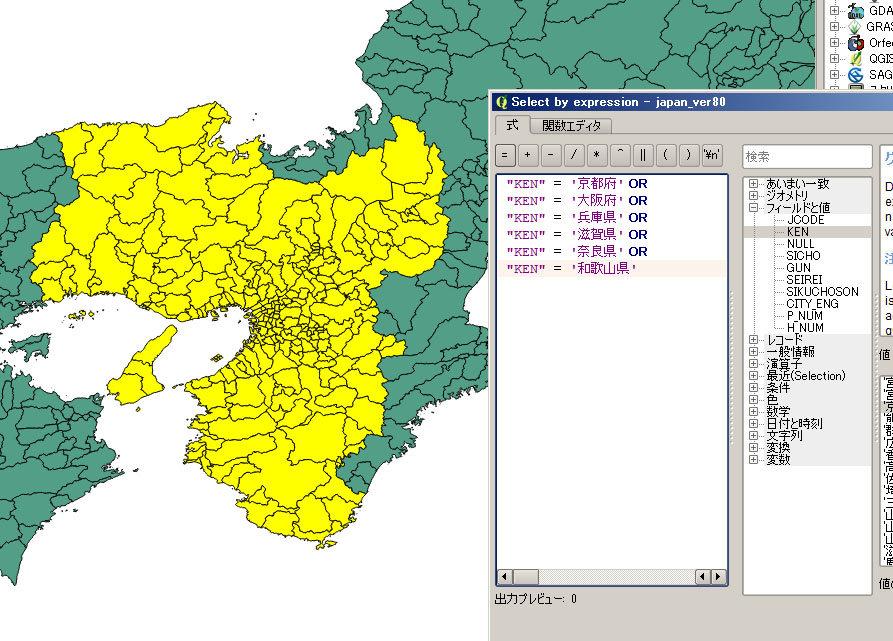
QGISを起動し、「japan_ver80.shp」を表示させる。その上で、下記の処理で関西二府四県の市町村を選択する。
「アドバンストフィルター」内で記述する式
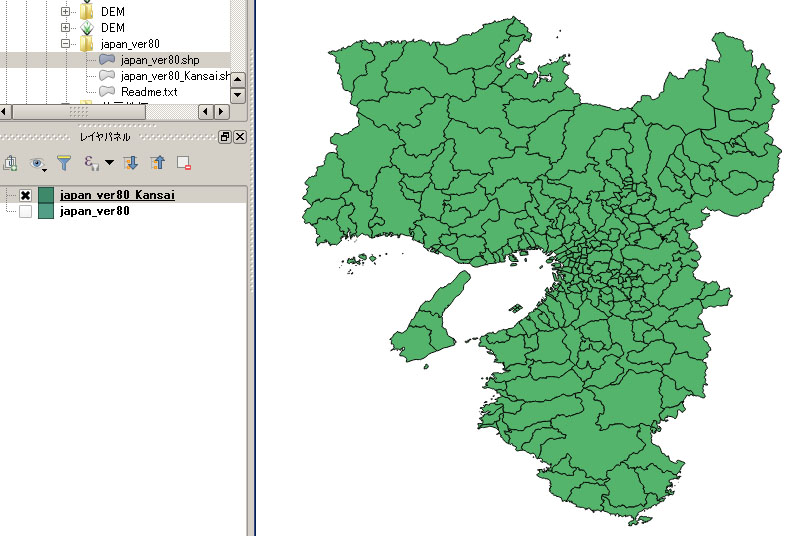
その後、選択した市町村を別のshapeファイルとして保存する。
|
|
| 選択された関西二府四県の市区町村 | 抽出後の関西二府四県の市区町村 |
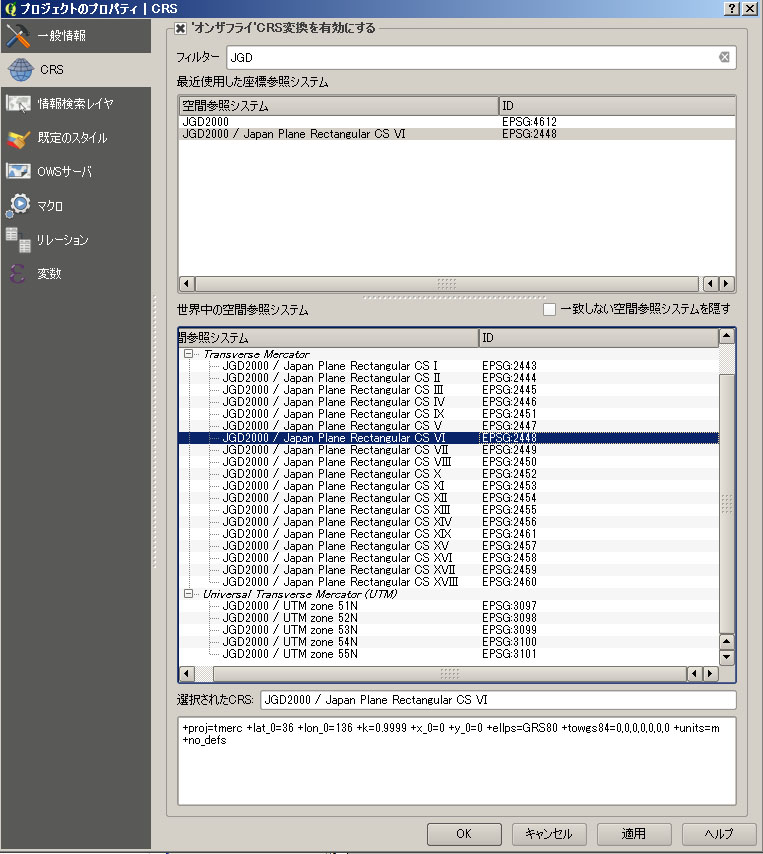
この後、各市町村の面積を計算する。但し、「japan_ver80_Kansai.shp」の「空間参照システム」が「JGD2000」であるため、そのまま計算すると面積が度の単位で返されてしまう。km2の単位での面積を求めるため、下記の処理を行う。
すると、平面直角座標系第6系で表示されるようになる。その後、 属性テーブルを開き、下記の処理を行う。
|
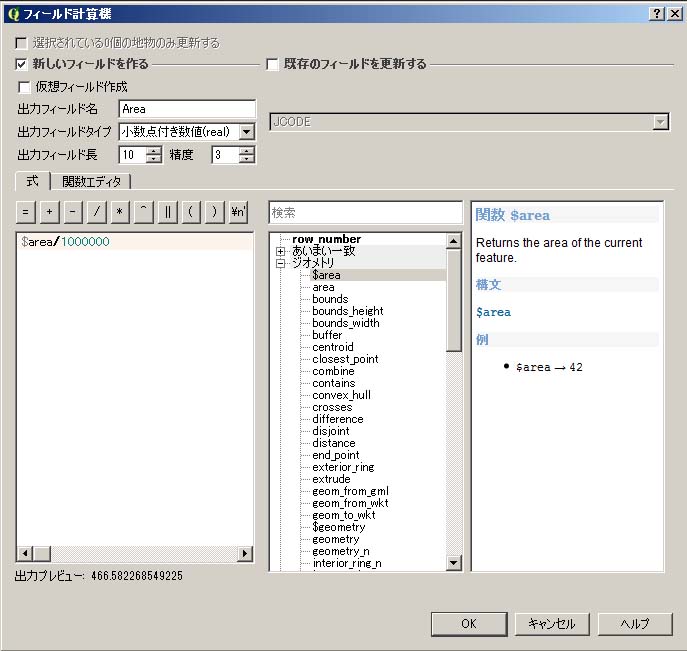
|
| 空間参照システムの変更 | フィールド計算機での計算式 |
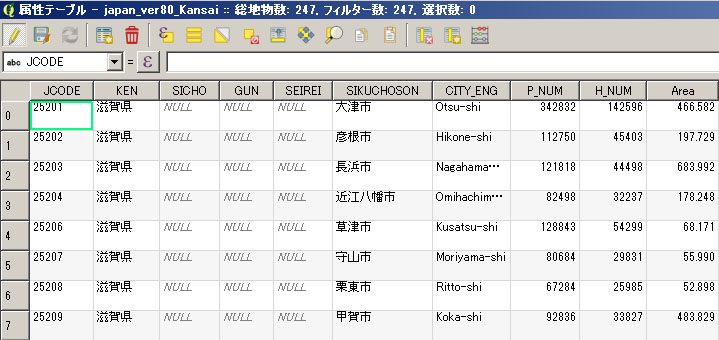
|
|
| km2単位の面積 |
公示地価データ「L01-10_26-g_LandPrice.shp」の「空間参照システム」は「JGD2000」である。上記の処理と同様に、一度別ファイルとして、平面直角座標系第6系が指定されたshapeファイルを保存する。(例えば、「L01-10_26-g_LandPrice_VI.shp」)
その後、属性テーブルを開き、下記の処理をフィールド名「X」と「Y」(共にm単位)について行う。
後の重回帰分析において特定地点との直線距離(本来なら移動に要する時間距離が望ましい)を用いる為、ここで計算する。以下、四条駅、大阪駅の平面直角座標系XI系での座標値(単位はm)を記す。これを利用して、上記で作成した「L01-10_26-g_LandPrice_VI.shp」の属性テーブル内に新たなフィールドを設け、距離を格納する。
まず、「昼夜間人口データ.xls」をExcelで開き、「平成22年」のワークシートを開く。各班で決定する課題においては種々の人口データを活用してほしいが、ここでは夜間人口と昼間人口に着目する。
一方、「japan_ver80_Kansai.shp」の属性テーブル「japan_ver80_Kansai.dbf」もExcelで開く。表1のように市区町村名で昇順に並び替えておく。この表を「昼夜間人口データ.xls」の新たなワークシート(例えば「面積」)に貼り付けておく。
表1:市区町村名で昇順に並び替えた「japan_ver80_Kansai.dbf」のデータの一部
SIKUCHOSON CITY_ENG P_NUM(人口) H_NUM(世帯数) Area 綾部市 Ayabe-shi 35419 15832 348.6 伊根町 Ine-cho 2339 941 61.2 井手町 Ide-cho 7899 3375 18.2 右京区 Kyoto-shi, Ukyo-ku 195921 92735 293.4 宇治市 Uji-shi 190856 81882 67.9 宇治田原町 Ujitawara-cho 9735 3572 58.5 下京区 Kyoto-shi, Shimogyo-ku 76814 42940 6.8 笠置町 Kasagi-cho 1529 675 23.6 亀岡市 Kameoka-shi 91548 37993 225.8 久御山町 Kumiyama-cho 16390 6809 13.9 宮津市 Miyazu-shi 19452 8694 174.2 京丹後市 Kyotango-shi 58514 22678 504.6 京丹波町 Kyotamba-cho 15555 6405 304.5 京田辺市 Kyotanabe-shi 66697 27001 43.1 向日市 Muko-shi 54340 23226 7.8 左京区 Kyoto-shi, Sakyo-ku 156069 77067 248.0 山科区 Kyoto-shi, Yamashina-ku 131699 63369 28.8 上京区 Kyoto-shi, Kamigyo-ku 76947 40677 7.1 城陽市 Joyo-shi 78560 34328 32.8 精華町 Seika-cho 37443 14269 25.9 西京区 Kyoto-shi, Nishikyo-ku 151827 66038 59.6 大山崎町 Oyamazaki-cho 15468 6427 6.1 中京区 Kyoto-shi, Nakagyo-ku 104345 55138 7.5 長岡京市 Nagaokakyo-shi 80222 34842 19.3 東山区 Kyoto-shi, Higashiyama-ku 37183 20688 7.5 南区 Kyoto-shi, Minami-ku 98433 48872 15.9 南山城村 Minamiyamashiro-mura 2961 1249 64.4 南丹市 Nantan-shi 33418 13958 619.2 八幡市 Yawata-shi 73038 31944 24.3 舞鶴市 Maizuru-shi 86996 40796 343.6 伏見区 Kyoto-shi, Fushimi-ku 278230 132889 61.9 福知山市 Fukuchiyama-shi 80682 35689 555.1 北区 Kyoto-shi, Kita-ku 112006 53017 95.2 木津川市 Kizugawa-shi 73095 27560 85.4 与謝野町 Yosano-cho 23318 9158 108.8 和束町 Wazuka-cho 4357 1751 65.3
ここで、「昼夜間人口データ.xls」の新たな列に、各市区町村の面積を参照するものとする。Excelでよく用いられるvlookupという関数を利用する。vlookupやhlookupは便利である反面、指定通りにデータを準備しないとエラーが返されるだけなので注意を要する。
(京都市)「北区」の面積を参照する関数
=VLOOKUP(B1224,面積!$A$1:$E$36,5)
vlookup時の注意点
夜間人口、昼間人口を上記の面積データで割って、人口密度データを計算する。下記の表2に一例を示す(関係のない列は割愛している)。
表2:市区町村名で昇順に並び替えた「昼夜間人口データ.xls」のデータの一部
(面積:km2、夜間人口密度・昼間人口密度:人/km2)
地域 夜間人口 昼間人口 面積 夜間人口密度 昼間人口密度 北区 122,037 129,464 95.2 1281.4 1359.3 上京区 83,264 97,833 7.1 11781.7 13843.2 左京区 168,802 176,443 248.0 680.7 711.5 中京区 105,306 155,123 7.5 14123.2 20804.4 東山区 40,528 56,253 7.5 5389.5 7480.6 下京区 79,287 135,656 6.8 11653.5 19938.6 南区 98,744 136,137 15.9 6208.6 8559.8 右京区 202,943 189,617 293.4 691.7 646.3 伏見区 284,085 276,715 61.9 4585.8 4466.8 山科区 136,045 121,223 28.8 4726.3 4211.4
公示地価データの属性テーブル「L01-10_26-g_LandPrice.dbf」をExcelで開く。このデータに上記で生成した、昼夜間人口密度データを付与していきたい。
各地点が属する市区町村名は「L01_018」のフィールドに記載されている。見ればわかるように、「京丹後」「福知山」のように、「~市」「~町」「~区」といった表示が割愛されている。また「京都市北区」「京都市南区」は「京都北」「京都南」と記述されている。今回も「vlookup」を用いて該当するデータを参照していく処理を考える。ただ参照元と参照先のデータ名を一致させておく必要がある。今回は参照先である「昼夜間人口データ.xls」の表記を変更するとする。
京都府のデータに限ると高々35個のデータなので、手動でもそれほど時間を要しない。ただ筆者が実施した処理を下記に紹介するので、参考にしてほしい。
この後、公示地価データの属性テーブル「L01-10_26-g_LandPrice.dbf」に「vlookup」を使って、昼夜間の人口密度データを付与する。vlookupの使い方は上記の説明と同じなので割愛する。
最後に、Excel上で今回の演習に関係のない列を削除して、表3に示すように列の項目名を変更する。その上で、CSVファイル「Kyoto10_Price.csv」として保存する。
表3:今回の演習に関係のない列を削除した最終的な「Kyoto10_Price.csv」(一部)
Price Name Station Dist2Station LU_Type X Y Dist2Shijo Dist2Osaka Pop_Day Pop_NightRを起動し、「Kyoto10_Price.csv」が存在するディレクトリへ移動する。
以下、Rでの実行画面を示す。赤字が入力文字を表す。
注意: spdepというライブラリを読み込んでいるが、一連の処理の最初に一度だけ実行すればいい。もしエラーが返されれば、「メニュー」→「パッケージ」からダウンロードして入手する。
> library(spdep)
> price <- read.table("Kyoto10_Price.csv", sep=",", header=TRUE)
> summary(price)
Price Name Station Dist2Station
Min. : 1150 伏見 : 60 北大路 : 24 Min. : 0
1st Qu.: 87375 左京 : 51 福知山 : 21 1st Qu.: 500
Median : 147000 宇治 : 50 桂 : 17 Median : 900
Mean : 180155 右京 : 43 大久保 : 16 Mean : 1321
3rd Qu.: 218250 山科 : 36 長岡天神: 15 3rd Qu.: 1600
Max. :3260000 京都北 : 33 亀岡 : 14 Max. :13000
(Other):407 (Other) :573
LU_Type X Y Dist2Shijo
1低専 :152 Min. :-88728 Min. :-141494 Min. : 256.3
1住居 : 87 1st Qu.:-27913 1st Qu.:-119458 1st Qu.: 4643.1
1住居,準防: 66 Median :-22850 Median :-112067 Median : 8369.8
近商,準防 : 48 Mean :-29012 Mean :-109713 Mean : 16753.7
調区 : 39 3rd Qu.:-19985 3rd Qu.:-106960 3rd Qu.: 18214.8
1中専 : 38 Max. :-11800 Max. : -34221 Max. :101389.6
(Other) :250
Dist2Osaka Pop_Day Pop_Night
Min. : 23617 Min. : 51.67 Min. : 47.58
1st Qu.: 33620 1st Qu.: 680.71 1st Qu.: 647.55
Median : 38864 Median : 2567.84 Median : 2091.09
Mean : 42718 Mean : 3402.11 Mean : 4043.03
3rd Qu.: 43643 3rd Qu.: 4585.75 3rd Qu.: 4466.78
Max. :117520 Max. :14123.18 Max. :20804.42
> coords <- matrix(0, nrow=nrow(price), ncol=2)
> coords[,1] <- price$X
> coords[,2] <- price$Y
> price.tri.nb <- tri2nb(coords)
# Moran's I test
> moran.test(price$Price, nb2listw(price.tri.nb, style="W"))
Moran I test under randomisation
data: price$Price
weights: nb2listw(price.tri.nb, style = "W")
Moran I statistic standard deviate = 22.865, p-value < 2.2e-16
alternative hypothesis: greater
sample estimates:
Moran I statistic Expectation Variance
0.4737820920 -0.0014727541 0.0004320206
# Geary's C test
> geary.test(price$Price, nb2listw(price.tri.nb, style="W"))
Geary C test under randomisation
data: price$Price
weights: nb2listw(price.tri.nb, style = "W")
Geary C statistic standard deviate = 9.1825, p-value < 2.2e-16
alternative hypothesis: Expectation greater than statistic
sample estimates:
Geary C statistic Expectation Variance
0.492007962 1.000000000 0.003060513
以下の手順に従って入力していく。
注意: 推定した結果はまとめて、「lm_result」というオブジェクトに保存されているが、個別の要素は「names()」を使って確認できる。Rでも図示できるようだが、筆者が確認した限りでは十分に鮮明な結果が得られなかった。そのため、本演習では推定結果の一部をファイルに出力し、QGIS上で図示するものとする。
> library(spdep)
> price <- read.table("Kyoto10_Price.csv", sep=",", header=TRUE)
> lm_result <- lm(Price~Dist2Shijo+X+Y+Pop_Night, data=price)
> summary(lm_result)
Call:
lm(formula = Price ~ Dist2Shijo + X + Y + Pop_Night, data = price)
Residuals:
Min 1Q Median 3Q Max
-300994 -55912 -11388 32065 2784660
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.962e+05 9.116e+04 5.443 7.34e-08 ***
Dist2Shijo -3.166e+00 7.200e-01 -4.397 1.28e-05 ***
X 9.232e-01 1.085e+00 0.851 0.395
Y 2.708e+00 6.334e-01 4.276 2.18e-05 ***
Pop_Night 1.507e+01 1.305e+00 11.548 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 167600 on 675 degrees of freedom
Multiple R-squared: 0.332, Adjusted R-squared: 0.328
F-statistic: 83.86 on 4 and 675 DF, p-value: < 2.2e-16
> names(lm_result)
[1] "coefficients" "residuals" "effects" "rank"
[5] "fitted.values" "assign" "qr" "df.residual"
[9] "xlevels" "call" "terms" "model"
> out.file <- file("Kyoto10_Price_rst.csv", open="w")
> x_str <- sprintf("%f,%f,%f,%f", price$X,
price$Y, price$Price, lm_result$residuals)(本当は1行で記述)
> writeLines(x_str, out.file)
> close(out.file)
推定結果をQGIS上で表示する。まず、上記の出力結果をGIS上に取り込む。
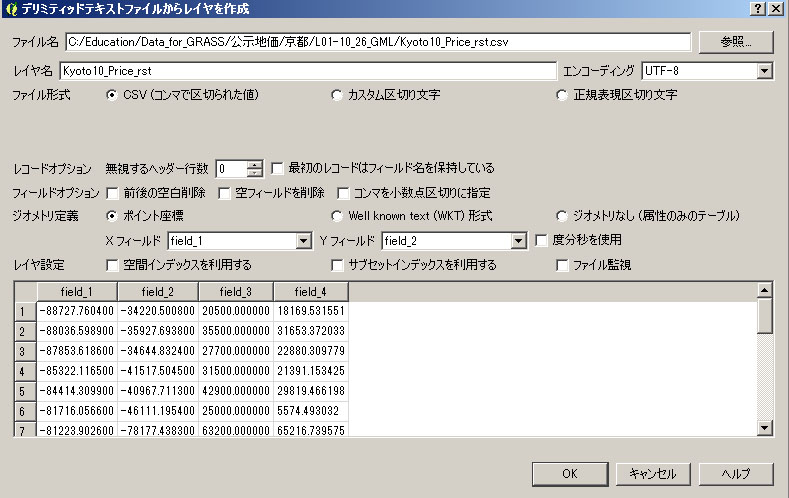 「デリミティッドテキストレイヤの追加」の様子
「デリミティッドテキストレイヤの追加」の様子
次に、他のデータと重ね合わせて表示させるためにも、上記のファイルに座標系を与えて保存する。
この時点で表示されている「Kyoto10_Price_rst」は表示画面から削除する。最終結果を分かりやすく表示させるために、下記のデータも事前にダウンロードし表示させておく。(注意:プロジェクトのCRSは「JGD2000」とし、「'オンザフライ'CRS変換を有効にする」にチェックを入れる)
最後に、上記で作成した「Kyoto10_Price_rst.shp」を表示させ、残差に応じて表示させる色を変えていく。
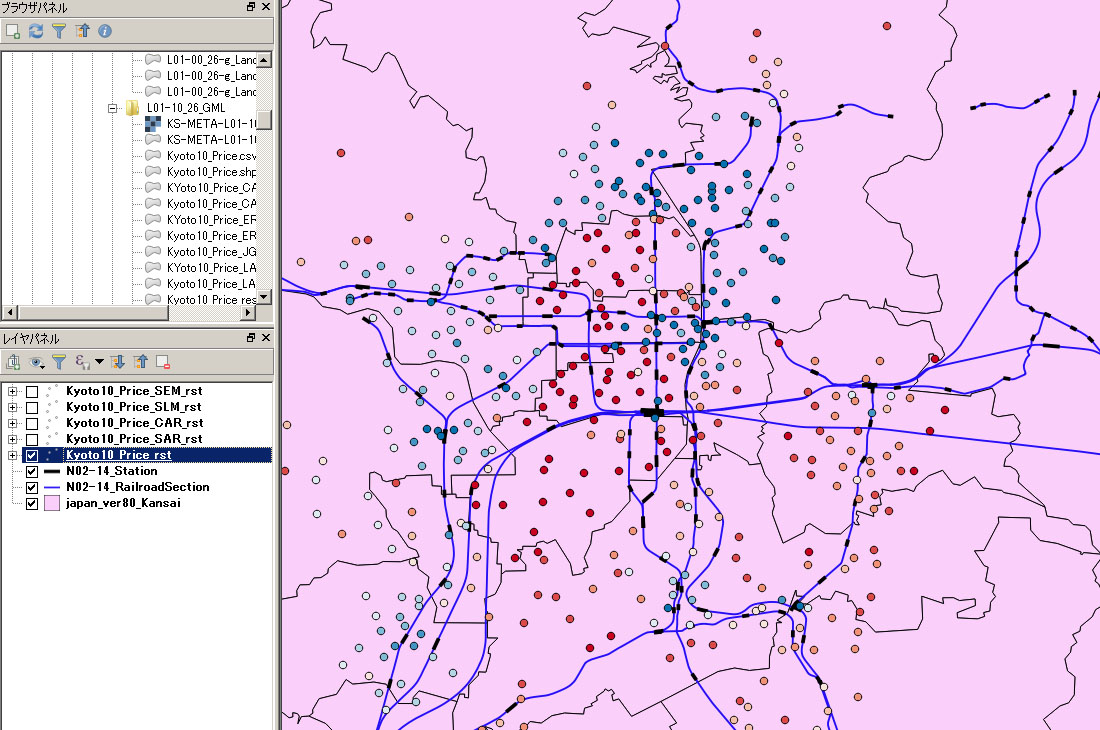 線形回帰モデルの推定結果。正負共に残差が大きい地点が多数散見され、推定に使用した線形モデルが不適切であると予想できる。
線形回帰モデルの推定結果。正負共に残差が大きい地点が多数散見され、推定に使用した線形モデルが不適切であると予想できる。
SARモデルパラメータ推定後の残差は、「SAR_result$fit$residuals」に格納されている点に注意する。
> sar_result <- spautolm(Price~Dist2Shijo+X+Y+Pop_Night,
data=price, nb2listw(price.tri.nb, style="W"),
family="SAR")
> summary(sar_result)
Call: spautolm(formula = Price ~ Dist2Shijo + X + Y + Pop_Night,
data = price, listw = nb2listw(price.tri.nb, style = "W"),
family = "SAR")
Residuals:
Min 1Q Median 3Q Max
-368324.8 -39917.1 -7905.6 19640.0 2727348.8
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 4.8938e+05 1.4055e+05 3.4820 0.0004977
Dist2Shijo -3.3432e+00 1.1068e+00 -3.0206 0.0025225
X 7.0138e-01 1.6624e+00 0.4219 0.6731003
Y 2.6339e+00 9.8222e-01 2.6816 0.0073277
Pop_Night 1.4370e+01 1.8322e+00 7.8427 4.441e-15
Lambda: 0.42335 LR test value: 72.818 p-value: < 2.22e-16
Numerical Hessian standard error of lambda: 0.046141
Log likelihood: -9105.795
ML residual variance (sigma squared): 2.4202e+10, (sigma: 155570)
Number of observations: 680
Number of parameters estimated: 7
AIC: 18226
> out.file <- file("Kyoto10_Price_SAR_rst.csv", open="w")
> x_str <- sprintf("%f,%f,%f,%f", price$X,
price$Y, price$Price, sar_result$fit$residuals)
> writeLines(x_str, out.file)
> close(out.file)
通常の回帰モデル推定後の処理と同様に、QGIS上で下記の処理を行うが、誤差分布の表示において注意を要する。
> car_result <- spautolm(Price~Dist2Shijo+X+Y+Pop_Night, data=
price, nb2listw(price.tri.nb, style="W"), family="CAR")
> summary(car_result)
Call: spautolm(formula = Price ~ Dist2Shijo + X + Y + Pop_Night,
data = price, listw = nb2listw(price.tri.nb, style = "W"),
family = "CAR")
Residuals:
Min 1Q Median 3Q Max
-747665.1 -25729.3 -3382.2 15782.7 2663876.8
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 487846.0530 172832.4135 2.8227 0.004763
Dist2Shijo -3.4955 1.3613 -2.5677 0.010237
X 0.5323 2.0235 0.2631 0.792508
Y 2.5498 1.2155 2.0976 0.035937
Pop_Night 14.4365 2.0666 6.9856 2.836e-12
Lambda: 0.81798 LR test value: 88.678 p-value: < 2.22e-16
Numerical Hessian standard error of lambda: 0.056908
Log likelihood: -9097.865
ML residual variance (sigma squared): 2.2514e+10, (sigma: 150050)
Number of observations: 680
Number of parameters estimated: 7
AIC: 18210
> out.file <- file("Kyoto10_Price_CAR_rst.csv", open="w")
> x_str <- sprintf("%f,%f,%f,%f", price$X,
price$Y, price$Price, car_result$fit$residuals)
> writeLines(x_str, out.file)
> close(out.file)
上記のSARモデル推定後と同様に処理する。
> slm_result <- lagsarlm(Price~Dist2Shijo+X+Y+Pop_Night,
data=price, nb2listw(price.tri.nb, style="W"))
> summary(lag_result)
Call:lagsarlm(formula = Price ~ Dist2Shijo + X + Y + Pop_Night,
data = price, listw = nb2listw(price.tri.nb, style = "W"))
Residuals:
Min 1Q Median 3Q Max
-385059.3 -37767.1 -7370.8 20333.0 2736621.4
Type: lag
Coefficients: (numerical Hessian approximate standard errors)
Estimate Std. Error z value Pr(>|z|)
(Intercept) 2.7271e+05 8.8270e+04 3.0895 0.002005
Dist2Shijo -1.7003e+00 6.9302e-01 -2.4534 0.014150
X 5.2089e-01 1.0165e+00 0.5125 0.608330
Y 1.4850e+00 6.0401e-01 2.4587 0.013946
Pop_Night 9.6840e+00 1.3386e+00 7.2344 4.676e-13
Rho: 0.42173, LR test value: 76.224, p-value: < 2.22e-16
Approximate (numerical Hessian) standard error: 0.044985
z-value: 9.3749, p-value: < 2.22e-16
Wald statistic: 87.889, p-value: < 2.22e-16
Log likelihood: -9104.092 for lag model
ML residual variance (sigma squared): 2.4088e+10, (sigma: 155200)
Number of observations: 680
Number of parameters estimated: 7
AIC: 18222, (AIC for lm: 18296)
> out.file <- file("Kyoto10_Price_SLM_rst.csv", open="w")
> x_str <- sprintf("%f,%f,%f,%f", price$X,
price$Y, price$Price, slm_result$residuals)
> writeLines(x_str, out.file)
> close(out.file)
> sem_result <- errorsarm(Price~Dist2Shijo+X+Y+Pop_Night,
data=price, nb2listw(price.tri.nb, style="W"))
> summary(err_result)
Call:errorsarlm(formula = Price ~ Dist2Shijo + X + Y + Pop_Night,
data = price, listw = nb2listw(price.tri.nb, style = "W"))
Residuals:
Min 1Q Median 3Q Max
-368324.8 -39917.1 -7905.6 19640.0 2727348.8
Type: error
Coefficients: (asymptotic standard errors)
Estimate Std. Error z value Pr(>|z|)
(Intercept) 4.8938e+05 1.4055e+05 3.4820 0.0004977
Dist2Shijo -3.3432e+00 1.1068e+00 -3.0206 0.0025225
X 7.0138e-01 1.6624e+00 0.4219 0.6731003
Y 2.6339e+00 9.8222e-01 2.6816 0.0073277
Pop_Night 1.4370e+01 1.8322e+00 7.8427 4.441e-15
Lambda: 0.42335, LR test value: 72.818, p-value: < 2.22e-16
Approximate (numerical Hessian) standard error: 0.046149
z-value: 9.1735, p-value: < 2.22e-16
Wald statistic: 84.153, p-value: < 2.22e-16
Log likelihood: -9105.795 for error model
ML residual variance (sigma squared): 2.4202e+10, (sigma: 155570)
Number of observations: 680
Number of parameters estimated: 7
AIC: 18226, (AIC for lm: 18296)
> out.file <- file("Kyoto10_Price_SEM_rst.csv", open="w")
> x_str <- sprintf("%f,%f,%f,%f", price$X,
price$Y, price$Price, sem_result$residuals)
> writeLines(x_str, out.file)
> close(out.file)
|
|
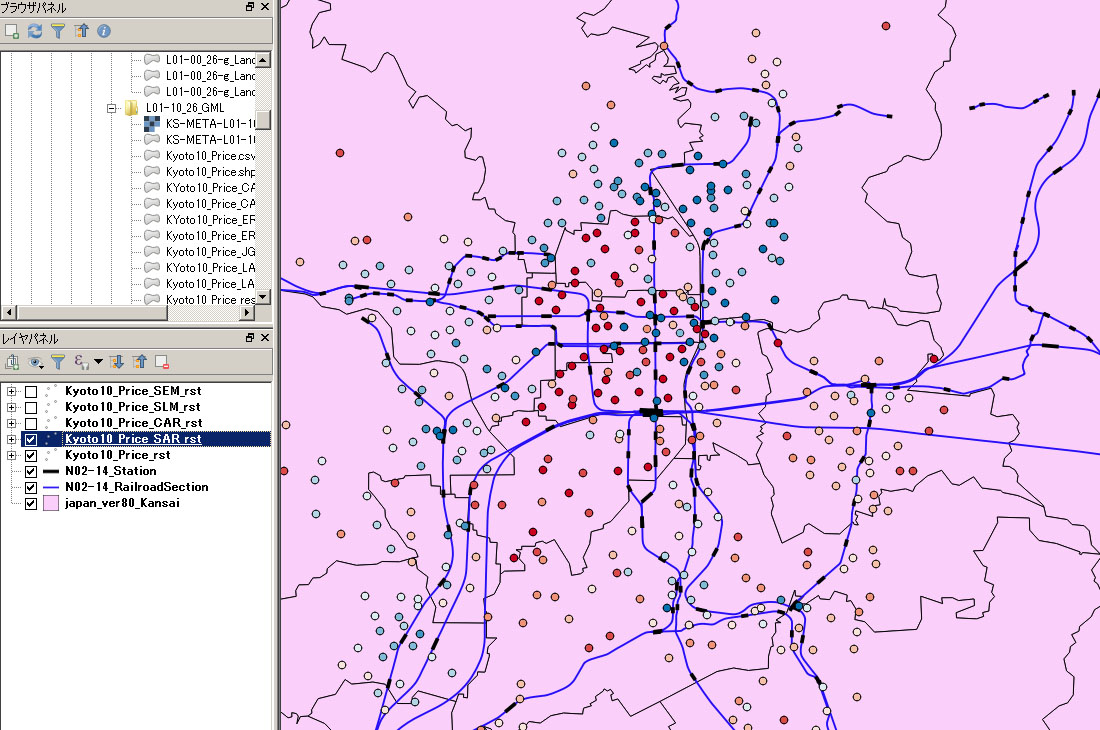
|
| 線形回帰モデルの推定結果 | 同時自己回帰モデル(SAR)の推定結果 |
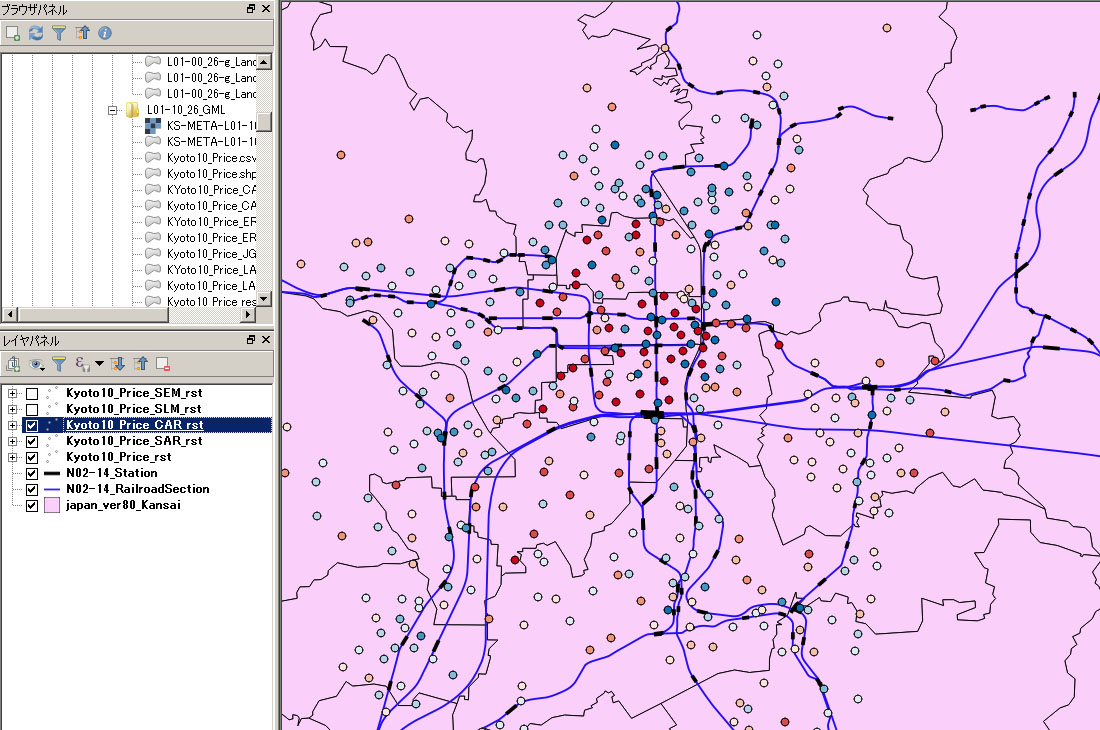
|
|
| 条件付き自己回帰モデル (CAR)の推定結果 |
空間的自己回帰モデル(SLM)の推定結果 |
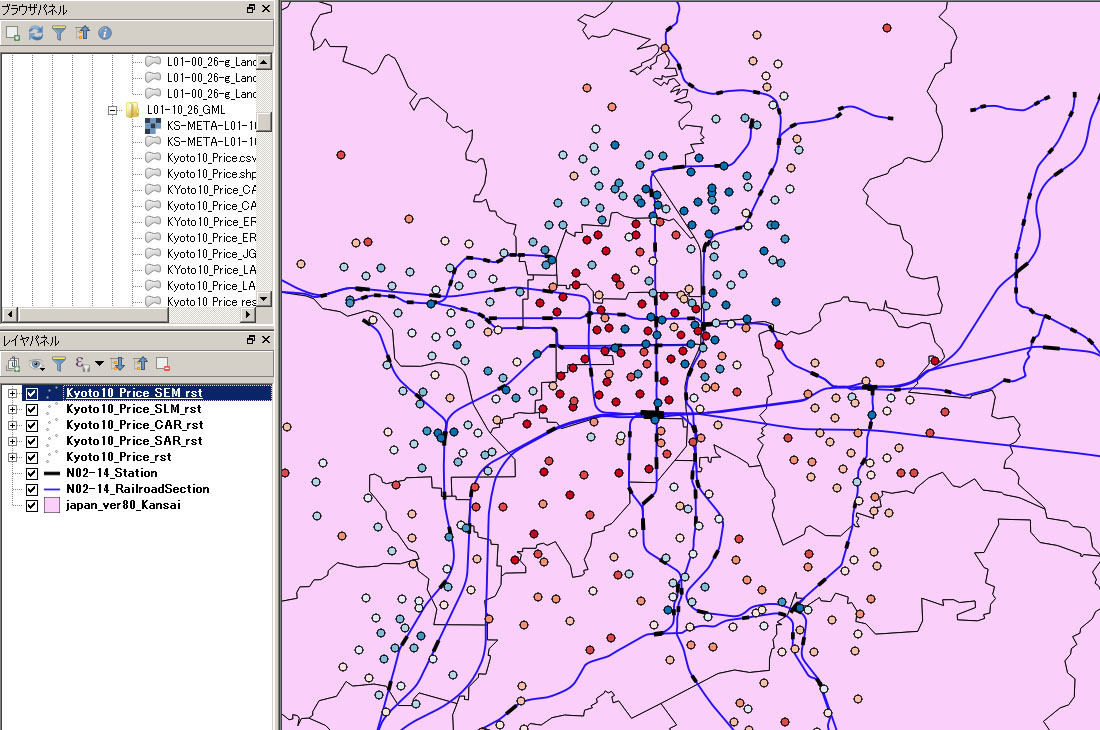
|
|
| 誤差項の空間的自己回帰モデル (SEM)の推定結果 |
各自で以下の課題に取り組んで、出力結果の画像(スクリーンショットでも可)も貼り付けて、レポートを完成せよ。
[GRASSのインストール、標高データを用いた地滑り危険度マップの作成]
[植生指数 (NDVI) の計算、表示]
[標高データ (SRTM)の表示、植生指数 (NDVI) の3次元表示]
[反射率、輝度温度、標高データを用いた土地被覆分類]
[QGIS, Rを用いた公示地価データの空間統計分析:空間的自己回帰モデル]
[QGIS, Rを用いた公示地価データの空間統計分析:静的な時空間モデリング]