情報大の建物検索
| No. | 建物 | 階数 | 特徴 | 画像 |
|---|---|---|---|---|
| 1 | 本館棟 | 7 | 講義室、演習室、事務局、ゼミ室 |  |
| 2 | 体育館棟 | 2 | アリーナ、トレーニングルーム |  |
| 3 | 学術フロンティア共同研究推進センター | 3 | 「社会環境」「自然環境」「環境情報システム開発」の国際共同研究の拠点 |  |
| 4 | 総合情報センター棟 | 3 | 電子図書館、メディア・ホール、スタジオ |  |
ここでは、XMLファイルからデータを取り出して一覧表示したり、検索対象の 文字列が存在するか調べたりします。最終的には、 「JSP: SVGファイルからのデータ検索」の ページで学習する内容である、地図画像であるSVGファイルも 組み込んだ形の検索を実現することを念頭に置いています。
まずは、このページのXMLファイル内の検索を実現するJSPファイルを作成 できるようになって下さい。段階的にJSPファイルを作り上げていきますので、 最初の演習から順次取り組んで下さい。
情報大の建物に関する下記のXMLファイルを利用していきます。ですが、Javaを 用いてXMLファイルを操作するときに、改行コード、および空白自体も 一つのタグ(Textタグ)として認識されます。 searchBuilding4.jsp以降は、改行コード、空白もあるXML ファイル (searchBuilding.xml) を対象にしますが、 searchBuilding3.jspまでは改行コード、 空白を取り除いたXMLファイル (searchBuilding_noSpace.xml) を 用意して使用していきます。
参考:XMLファイルの改行コードに関して
そこで、秀丸を用いた正規表現による処理で、 改行コードと空白の除去を実現していきます。 秀丸での正規表現の処理は練習しましたが、忘れた方は 「秀丸での検索、置換」のページを確認してください。
準備: こちらのファイルをコピーして、秀丸上で貼り付けてください。
ファイル名:searchBuilding.xml
第1段階:改行コードの除去
特に説明しませんが、もし忘れた場合には、 「秀丸での検索、置換」のページの改行コードの説明を読み直してください。
ファイル名:searchBuilding_noSpace.xml
第2段階:>と<との間の空白の除去
空白を除去すると言いましても、 <building id="1">に現れる空白ではなく、
のように、>と<との間に存在する空白のみを対象とします。このような空白 だけを除去する正規表現を考えた上で、秀丸上で処理してみてください。
第3段階:>と<との間のタブの除去(もしあれば)
処理の手順は第2段階と同様に行いますが、秀丸でタブを正規表現で表すと、 \tとなります。今回使用しているファイルにはタブは含ま れていませんが、覚えておくと便利でしょう。
第4段階:画像URLデータの修正
処理されているデータには、画像のURLを示す<url>、および サムネール画像のURLを示す<thumnailurl>という要素があります。 現在の段階では私のWebサイトにある画像のURLが記述されていますが、 それらを全て自分自身の画像のURLに 変更してください。例えば、
という状況の場合、下記のように変更します。
注意:searchBuilding.xmlに対しても、この第4段階の処理 を行ってください。
上記の処理ができているという前提で、下の「XMLファイルからのデータの 読み込み」の演習を行っていきます。
下記のsearchBuilding1.jspでは、 単純に、XMLファイルからデータを読み込んできて一覧表示するだけの処理を 行っています。ソースの後に簡単な説明が書いてあります。
searchBuilding1.jsp
<%@page contentType="text/html;charset=Shift_JIS"%>
<%@page import="java.io.*, org.apache.xerces.parsers.*, org.xml.sax.*, org.w3c.dom.*" %>
<html>
<head><title>情報大の建物検索</title></head>
<body>
<h1>情報大の建物検索</h1>
<table border="1">
<tr>
<th>No.</th><th>建物</th><th>階数</th><th>特徴</th><th>画像URL</th><th>サムネール画像URL</th>
</tr>
<%
DOMParser prs = new DOMParser();
FileReader fr = new FileReader(application.getRealPath("searchBuilding_noSpace.xml"));
BufferedReader br = new BufferedReader(fr);
InputSource src = new InputSource(br);
prs.parse(src);
Document objDoc = prs.getDocument();
Element objRoot = objDoc.getDocumentElement();
NodeList cldNod = objRoot.getChildNodes();
for (int i=0; i < cldNod.getLength(); i++) {
out.println("<tr>");
Node objNod = cldNod.item(i);
NamedNodeMap clnNnm = objNod.getAttributes();
Attr atrNam = (Attr)clnNnm.item(0);
out.println("<td>" + atrNam.getValue() + "</td>");
NodeList cldNod2 = objNod.getChildNodes();
for (int j=0; j < cldNod2.getLength(); j++) {
Node objNod2 = cldNod2.item(j);
out.println("<td>" + objNod2.getFirstChild().getNodeValue() + "</td>");
}
out.println("</tr>");
}
%>
</table>
</body>
</html>
注意点をかいつまんで説明していきます。XMLファイルを開く箇所ですが、下記 のようにgetRealPathメソッドで、ファイルの 絶対パスを取得しています。大学の演習室の環境では、 searchBuilding1.jspとsearchBuilding_noSpace.xmlを同じディレクトリに保存 している場合には、上記の記述で正常に動作するはずです。
実行時に「ファイルが見つかりません」というエラーが表示されたら、 このファイルのパスの記述が間違っているということです。その場合には、 適宜修正するよう注意してください。
次に、パーサーであるDOM (Document Object Model) に関する記述です。 XMLファイルを読み込むのに、DOMやSAXがありますが、ここではDOMを利用して います。そのための記述です。
参考: e-Wordsで調べてみよう
DOMParser prs = new DOMParser();
FileReader fr = new FileReader(application.getRealPath("searchBuilding_noSpace.xml"));
BufferedReader br = new BufferedReader(fr);
InputSource src = new InputSource(br);
prs.parse(src);
そして、ルートに対して、
Element objRoot = objDoc.getDocumentElement(); NodeList cldNod = objRoot.getChildNodes();
のように設定して、ルート以下のノードのデータを、NodeListクラスのインスタンス、 cldNodに与えています。
を使って、ルート以下のノード数(building要素の数)を取り出しています。
そして、buildingの中の属性idを取り出すのに、
を使っています。
最後になりますが、buildingノードの中にある、各ノード(nameやfloorなど) の値を取り出すのに、
を使っています。
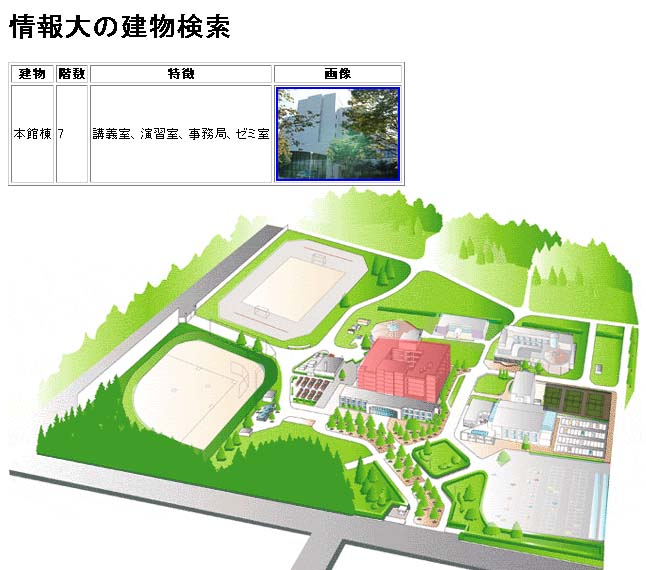
それでは、searchBuilding1.jspの実行結果を確認してみましょう。単に、XMLファ イルの要素値が抽出されて、table形式で表示されているだけです。 この形を出発点として、段階的に発展させていきます。
searchBuilding1.jspの実行結果: 学生会館「ピオーネ」以降の表示は割愛
| No. | 建物 | 階数 | 特徴 | 画像URL | サムネール画像URL |
|---|---|---|---|---|---|
| 1 | 本館棟 | 7 | 講義室、演習室、事務局、ゼミ室 | http://www.gi.ce.t.kyoto-u.ac.jp/user/susaki/envinfo/image/mainbuilding1.jpg | http://www.gi.ce.t.kyoto-u.ac.jp/user/susaki/envinfo/image/mainbuilding1_min.jpg |
| 2 | 体育館棟 | 2 | アリーナ、トレーニングルーム | http://www.gi.ce.t.kyoto-u.ac.jp/user/susaki/envinfo/image/gym1.jpg | http://www.gi.ce.t.kyoto-u.ac.jp/user/susaki/envinfo/image/gym1_min.jpg |
| 3 | 学術フロンティア共同研究推進センター | 3 | 「社会環境」「自然環境」「環境情報システム開発」の国際共同研究の拠点 | http://www.gi.ce.t.kyoto-u.ac.jp/user/susaki/envinfo/image/frontier1.jpg | http://www.gi.ce.t.kyoto-u.ac.jp/user/susaki/envinfo/image/frontier1_min.jpg |
| 4 | 総合情報センター棟 | 3 | 電子図書館、メディア・ホール、スタジオ | http://www.gi.ce.t.kyoto-u.ac.jp/user/susaki/envinfo/image/infocenter1.jpg | http://www.gi.ce.t.kyoto-u.ac.jp/user/susaki/envinfo/image/infocenter1_min.jpg |
それでは、要素名を抽出して、表示させてみましょう。 「searchBuilding1.jsp」に、下記の赤字の部分を追記して、 「searchBuilding2.jsp」として保存しましょう。
searchBuilding2.jsp
<%@page contentType="text/html;charset=Shift_JIS"%>
<%@page import="java.io.*, org.apache.xerces.parsers.*, org.xml.sax.*, org.w3c.dom.*" %>
<html>
<head><title>情報大の建物検索</title></head>
<body>
<h1>情報大の建物検索</h1>
<table border="1">
<tr>
<th>No.</th><th>建物</th><th>階数</th><th>特徴</th><th>画像URL</th><th>サムネール画像URL</th>
</tr>
<%
DOMParser prs = new DOMParser();
FileReader fr = new FileReader(application.getRealPath("searchBuilding_noSpace.xml"));
BufferedReader br = new BufferedReader(fr);
InputSource src = new InputSource(br);
prs.parse(src);
Document objDoc = prs.getDocument();
Element objRoot = objDoc.getDocumentElement();
NodeList cldNod = objRoot.getChildNodes();
for (int i=0; i < cldNod.getLength(); i++) {
out.println("<tr>");
Node objNod = cldNod.item(i);
NamedNodeMap clnNnm = objNod.getAttributes();
Attr atrNam = (Attr)clnNnm.item(0);
out.println("<td>" + atrNam.getValue() + "</td>");
NodeList cldNod2 = objNod.getChildNodes();
for (int j=0; j < cldNod2.getLength(); j++) {
Node objNod2 = cldNod2.item(j);
out.println("<td>" + objNod2.getNodeName() + "<br />" + objNod2.getFirstChild().getNodeValue() + "</td>");
}
out.println("</tr>");
}
%>
</table>
</body>
</html>
searchBuilding2.jspの実行結果: 学生会館「ピオーネ」以降の表示は割愛
| No. | 建物 | 階数 | 特徴 | 画像URL | サムネール画像URL |
|---|---|---|---|---|---|
| 1 | name 本館棟 |
floor 7 |
comment 講義室、演習室、事務局、ゼミ室 |
url http://www.gi.ce.t.kyoto-u.ac.jp/user/susaki/envinfo/image/mainbuilding1.jpg |
thumnail_url http://www.gi.ce.t.kyoto-u.ac.jp/user/susaki/envinfo/image/mainbuilding1_min.jpg |
| 2 | name 体育館棟 |
floor 2 |
comment アリーナ、トレーニングルーム |
url http://www.gi.ce.t.kyoto-u.ac.jp/user/susaki/envinfo/image/gym1.jpg |
thumnail_url http://www.gi.ce.t.kyoto-u.ac.jp/user/susaki/envinfo/image/gym1_min.jpg |
| 3 | name 学術フロンティア共同研究推進センター |
floor 3 |
comment 「社会環境」「自然環境」「環境情報システム開発」の国際共同研究の拠点 |
url http://www.gi.ce.t.kyoto-u.ac.jp/user/susaki/envinfo/image/frontier1.jpg |
thumnail_url http://www.gi.ce.t.kyoto-u.ac.jp/user/susaki/envinfo/image/frontier1_min.jpg |
| 4 | name 総合情報センター棟 |
floor 3 |
comment 電子図書館、メディア・ホール、スタジオ |
url http://www.gi.ce.t.kyoto-u.ac.jp/user/susaki/envinfo/image/infocenter1.jpg |
thumnail_url http://www.gi.ce.t.kyoto-u.ac.jp/user/susaki/envinfo/image/infocenter1_min.jpg |
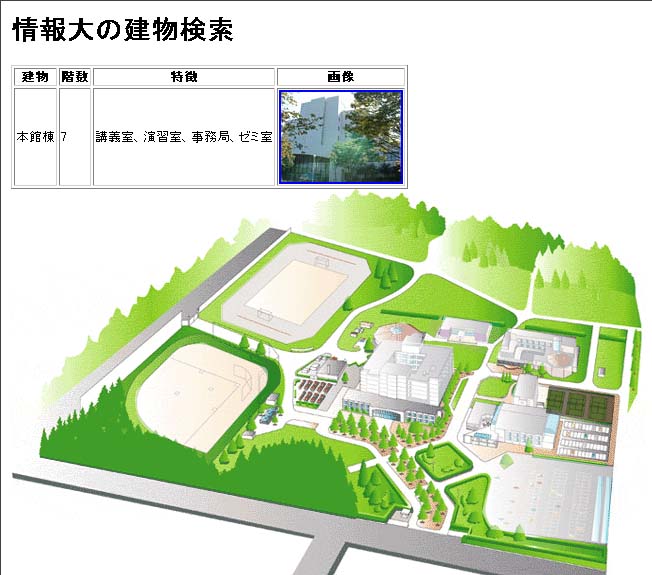
上記の「searchBuilding2.jsp」を踏まえて、サムネール画像を 表示し、画像をクリックすると原画像が表示されるようにしたい。 そのような処理を実現するJSPファイルを、searchBuilding3.jspとして 作成し、動作確認せよ。以下に示すような結果となる。
searchBuilding3.jspの実行結果: 学生会館「ピオーネ」以降の表示は割愛
| No. | 建物 | 階数 | 特徴 | 画像 |
|---|---|---|---|---|
| 1 | 本館棟 | 7 | 講義室、演習室、事務局、ゼミ室 | |
| 2 | 体育館棟 | 2 | アリーナ、トレーニングルーム | |
| 3 | 学術フロンティア共同研究推進センター | 3 | 「社会環境」「自然環境」「環境情報システム開発」の国際共同研究の拠点 | |
| 4 | 総合情報センター棟 | 3 | 電子図書館、メディア・ホール、スタジオ | |
それでは今度は、HTMLページ上で検索条件を指定して、送信されてきたデータに 基づいて検索するJSPファイルを作りましょう。下記に示してある、 searchBuilding4.htmlとsearchBuilding4.jspを作成し、動作確認しましょう。
ただし、searchBuilding4.jsp中のうち、「サムネール画像の表示と 原画像へのリンク」に関する処理は、「********************」で隠されていま す。上記のsearchBuilding3.jspと同じ処理を記述すればいいだけの話です。
注意:ここでは、入力ファイルとして、 searchBuilding.xmlを使用しています。
searchBuilding4.html
<html> <head> <title>情報大の建物検索</title> </head> <body> <form method="post" action="searchBuilding4.jsp"> <p> 検索したい建物を選んで下さい </p> <input type="radio" name="buildingName" value="本館棟" checked="checked" />本館棟<br /> <input type="radio" name="buildingName" value="体育館棟" />体育館棟<br /> <input type="radio" name="buildingName" value="学術フロンティア共同研究推進センター" /> 学術フロンティア共同研究推進センター<br /> <input type="radio" name="buildingName" value="総合情報センター棟" />総合情報センター棟<br /> <input type="radio" name="buildingName" value="学生会館「ピオーネ」" />学生会館「ピオーネ」<br /> <input type="radio" name="buildingName" value="食堂棟" />食堂棟<br /> <input type="radio" name="buildingName" value="野球部グラウンド" />野球部グラウンド<br /> <input type="radio" name="buildingName" value="グラウンド" />グラウンド<br /> <input type="radio" name="buildingName" value="テニスコート" />テニスコート<br /> <input type="radio" name="buildingName" value="駐車場" />駐車場<br /> <input type="radio" name="buildingName" value="部室棟I・II" />部室棟I・II<br /> <br /> <input type="submit" value="送信" /> </form> </body> </html>
searchBuilding4.jsp
<%@page contentType="text/html;charset=Shift_JIS"%>
<%@page import="java.io.*, org.apache.xerces.parsers.*, org.xml.sax.*, org.w3c.dom.*" %>
<html>
<head><title>情報大の建物検索</title></head>
<body>
<h1>情報大の建物検索</h1>
<%
request.setCharacterEncoding("Shift_JIS");
String searchName = request.getParameter("buildingName");
DOMParser prs = new DOMParser();
FileReader fr = new FileReader(application.getRealPath("searchBuilding.xml"));
BufferedReader br = new BufferedReader(fr);
InputSource src = new InputSource(br);
prs.parse(src);
Document objDoc = prs.getDocument();
Element objRoot = objDoc.getDocumentElement();
NodeList cldNod = objRoot.getChildNodes();
int i_match = 0, flag = 0;
for (int i=0; i < cldNod.getLength(); i++) {
Node objNod = cldNod.item(i);
NodeList cldNod2 = objNod.getChildNodes();
for (int j=0; j < cldNod2.getLength(); j++) { // 該当の建物の検索
Node objNod2 = cldNod2.item(j);
if (objNod2.getNodeName().equals("name")) { // name 要素の抽出
// 検索対象とのマッチング
if (objNod2.getFirstChild().getNodeValue().equals(searchName)) {
i_match = i;
flag = 1;
break;
}
}
}
}
if (flag == 1) { // マッチしたデータが存在する場合
Node objNod = cldNod.item(i_match);
NodeList cldNod2 = objNod.getChildNodes();
// 変数の初期化
String floorValue = new String();
String commentValue = new String();
String urlValue = new String();
String thumnailUrlValue = new String();
for (int j=0; j < cldNod2.getLength(); j++) {
Node objNod2 = cldNod2.item(j);
String nodName = objNod2.getNodeName();
if (objNod2.getNodeName().equals("floor")) {
// floor要素の値の抽出
floorValue = objNod2.getFirstChild().getNodeValue();
} else if (objNod2.getNodeName().equals("comment")) {
// comment要素の値の抽出
commentValue = objNod2.getFirstChild().getNodeValue();
} else if (objNod2.getNodeName().equals("url")) {
// url要素の値の抽出
urlValue = objNod2.getFirstChild().getNodeValue();
} else if (objNod2.getNodeName().equals("thumnail_url")) {
// thumnail_url要素の値の抽出
thumnailUrlValue = objNod2.getFirstChild().getNodeValue();
}
}
// table形式での出力
out.println("<table border=\"1\">");
out.println("<tr>");
out.println("<th>建物</th><th>階数</th><th>特徴</th><th>画像</th>");
out.println("</tr>");
out.println("<tr>");
out.println("<td>" + searchName + "</td>");
out.println("<td>" + floorValue + "</td>");
out.println("<td>" + commentValue + "</td>");
// サムネール画像の表示と原画像へのリンク
out.println(*************************************************);
out.println("</tr>");
out.println("</table>");
} else { // マッチするデータが存在しない場合
out.println("<p>該当の建物は見つかりませんでした</p>");
}
%>
</body>
</html>
以下に、実行例が示されています。
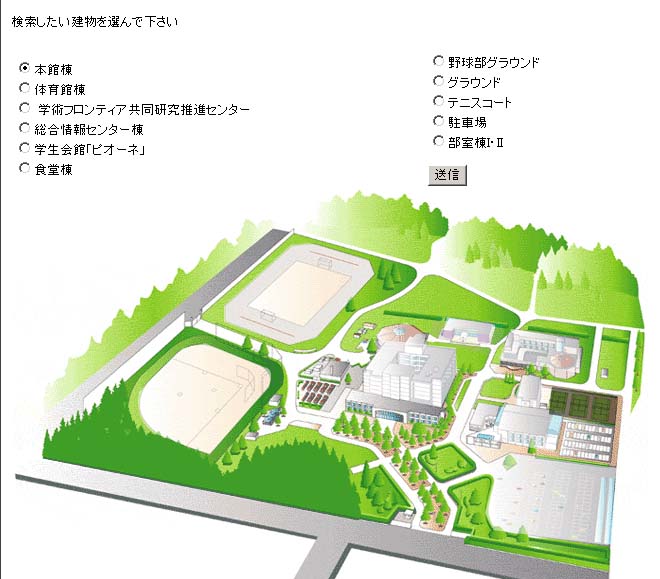
searchBuilding4.htmlの画面: searchBuilding4.htmlで「学生会館「ピオーネ」」を選び、そのデータが 次のsearchBuilding4.jspに送信される
検索したい建物を選んで下さい
本館棟searchBuilding4.jspの実行結果: searchBuilding4.htmlで「学生会館「ピオーネ」」を選んだ結果
| 建物 | 階数 | 特徴 | 画像 |
|---|---|---|---|
| 学生会館「ピオーネ」 | 2 | 部活動、サークル、学園祭などの課外活動の拠点 |  |
上記の演習を元に、SVG画像を取り込んだ形の検索を実現したい。
searchBuilding5.htmlの画面:
searchBuilding5.jspの実行結果:
searchBuilding6.html:searchBuilding5.htmlと同じなの で省略
searchBuilding6.jspの実行結果: 選択された本館棟がアニメーション表示されている